Eureka
Eureka停更说明
https://github.com/Netflix/eureka/wiki
Eureka 2.0 (Discontinued)
The existing open source work on eureka 2.0 is discontinued. The code base and artifacts that were released as part of the existing repository of work on the 2.x branch is considered use at your own risk.
Eureka 1.x is a core part of Netflix’s service discovery system and is still an active project.
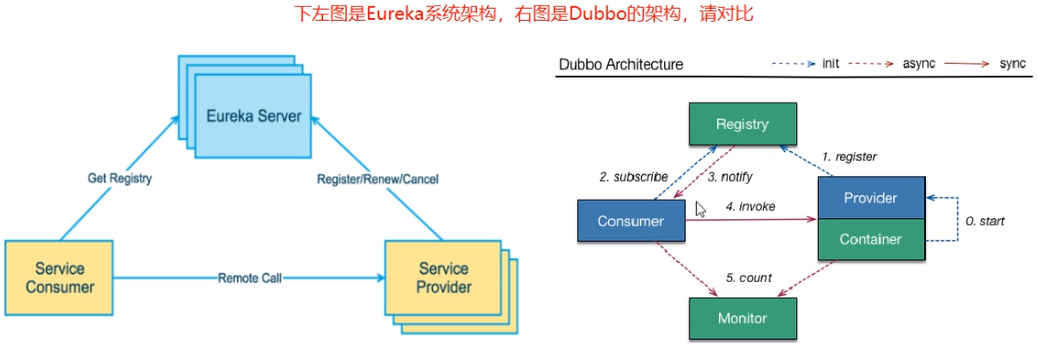
服务治理
SpringCloud封装了Netflix开发的Eureka来实现服务治理。
传统RPC远程调用框架中,服务之间依赖关系复杂,不便于管理。所以产生了服务治理,实现服务的注册与发现。
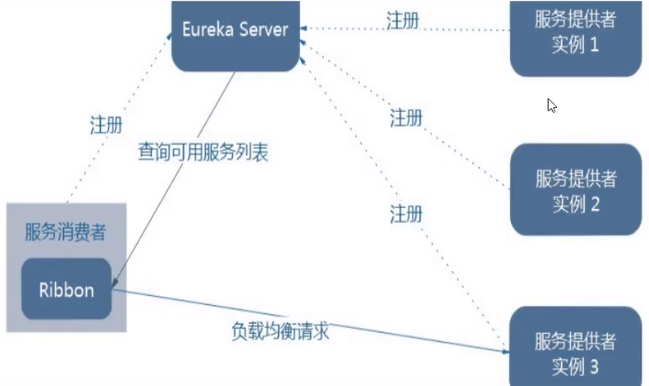
服务的注册与发现
各服务(Eureka Client)往注册中心(Eureka Server)注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
心跳机制
- 服务器启动成功,等待客户(服务)端注册,在启动过程中如果我们配置了集群,集群之间会同步注册表,每一个Eureka serve都会存在这个集群完整的服务注册表信息
- Eureka client 启动时根据配置信息,去注册到指定的注册中心
- Eureka client会每30秒向Eureka server 发送一次心跳请求,证明该客户端服务正常
- 当Eureka server90s内没有接受客户端服务正常,注册中心会认为该节点失效,会注销该实列 (从注册表中删除注册信息)
- 单位时间内如果服务端统计到大量客户端没有发送心跳,则认为网络异常,进去自我保护机制,不在剔除没有发送心跳的客户端
- 当客户端恢复正常之后,服务端就会退出自我保护模式
- 客户端定时全量或增量从注册中心获取服务注册表,并且会缓存到本地
- 服务调用时,客户端会先从本地缓存找到调用服务,如果调取不到 先从注册中心刷新注册表,在同步到本地
- 客户端获取不到目标服务器信息发起服务调用
- 客户端程序关闭时向服务端发送取消请求,服务器将实例从注册表中删除
自我保护机制
在默认配置中,Eureka Server在默认90s没有得到客户端的心跳,则注销该实例,但是往往因为微服务跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,但是因为网络分区故障时,Eureka Server注销服务实例则会让大部分微服务不可用,这很危险,因为服务明明没有问题。
为了解决这个问题,Eureka 有自我保护机制,通过在Eureka Server配置如下参数,可启动保护机制
eureka.server.enable-self-preservation=true。它的原理是,当Eureka Server节点在短时间内丢失过多的客户端时(可能发送了网络故障),那么这个节点将进入自我保护模式,不再注销任何微服务,当网络故障回复后,该节点会自动退出自我保护模式。
自我保护模式的架构哲学是宁可放过一个,决不可错杀一千
Eureka比Zookeeper好在哪里
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
实战
注册中心:cloud-eureka-server7001
maven pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>application.yml
server:
port: 7001
eureka:
instance:
hostname: locathost #eureka服务端的实例名称
client:
#false表示不向注册中心注册自己。
register-with-eureka: false
#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
fetch-registry: false
service-url:
#设置与Eureka server交互的地址查询服务和注册服务都需要依赖这个地址。
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/服务消费者:cloud-consumer-order1080
maven pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>application.yml
server:
port: 1080
spring:
application:
name: cloud-order-service
eureka:
instance:
# 注册中心展示的名称
instance-id: order1080
# 注册中心实例展示ip地址
prefer-ip-address: true
client:
#表示是否将自己注册进Eurekaserver默认为true。
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetchRegistry: true
service-url:
defaultZone: http://localhost:7001/eureka服务提供者:cloud-provider-payment8001
maven pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>application.yml
server:
port: 8001
spring:
application:
name: cloud-payment-service
datasource:
type: com.alibaba.druid.pool.DruidDataSource # 当前数据源操作类型
driver-class-name: org.gjt.mm.mysql.Driver # mysql驱动包
url: jdbc:mysql://${mysql.addr}/cloud2020?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: ${mysql.user}
password: ${mysql.pwd}
mybatis:
mapperLocations: classpath:mapper/*.xml
type-aliases-package: com.yuyy.springcloud.entities # 所有Entity别名类所在包
eureka:
instance:
instance-id: payment8001
prefer-ip-address: true
client:
#表示是否将自己注册进Eurekaserver默认为true。
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetchRegistry: true
service-url:
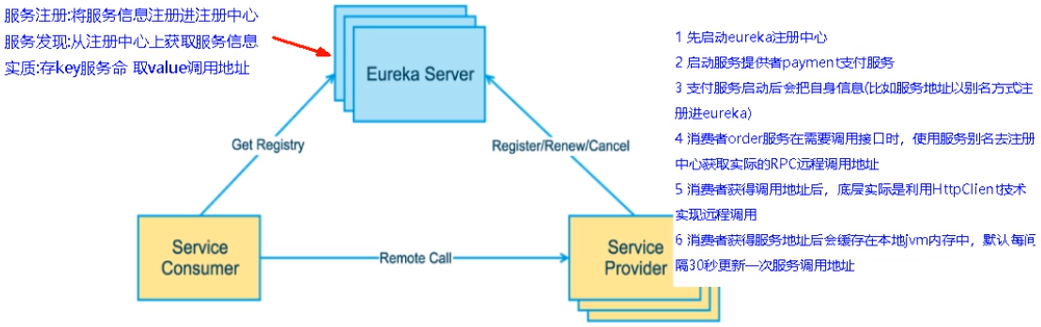
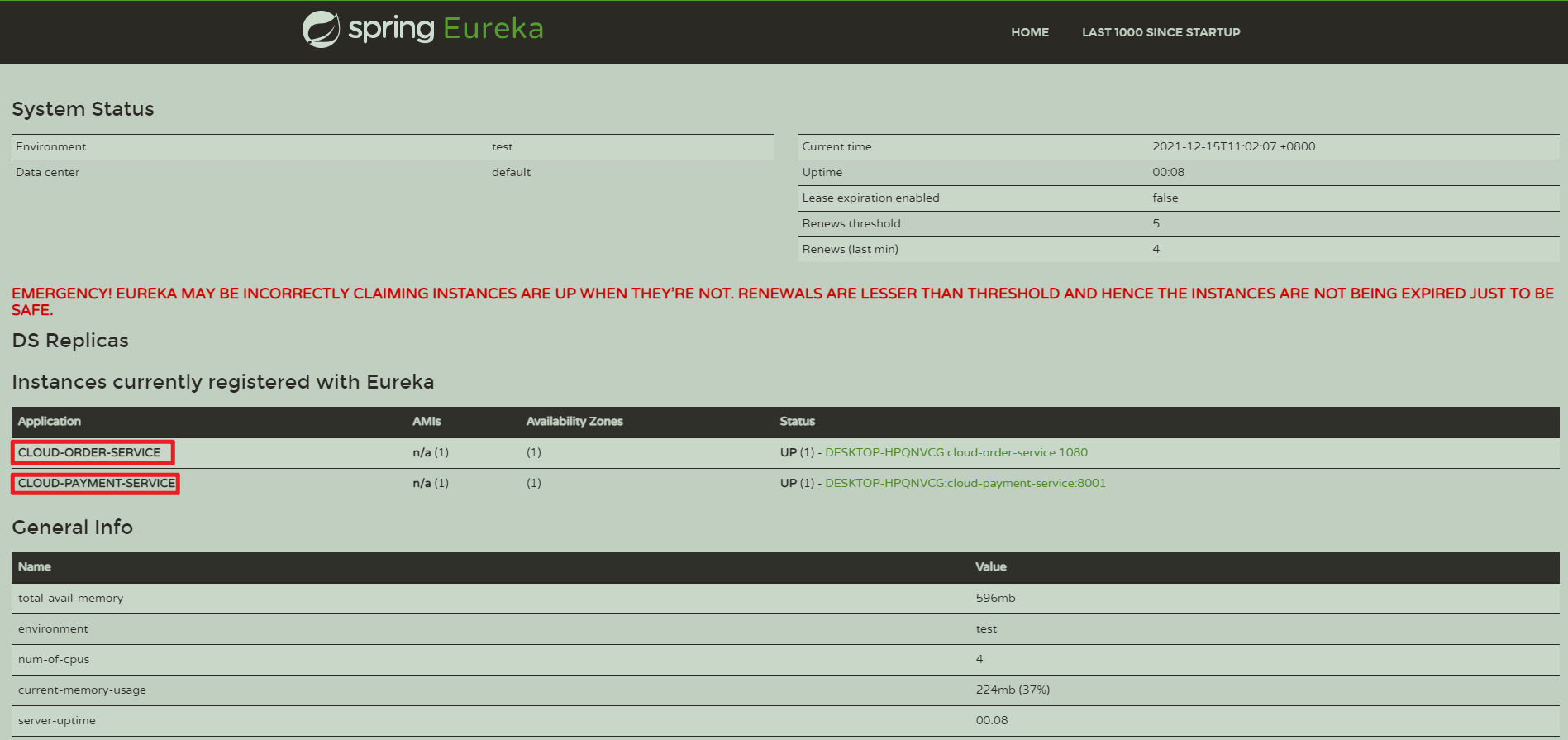
defaultZone: http://localhost:7001/eureka访问注册中心
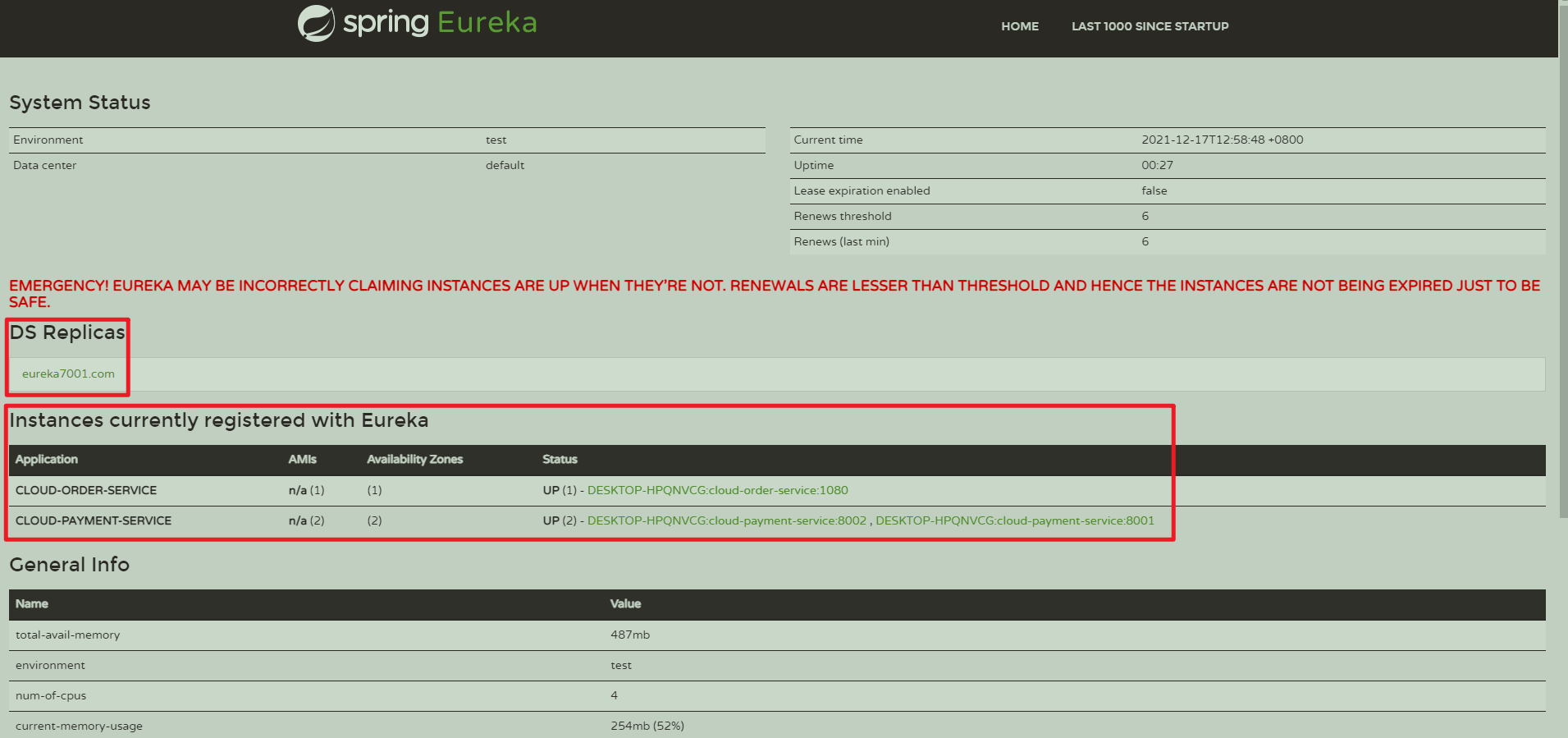
http://localhost:7001,可以看到已经注册上的Eureka Client
eureka:
instance:
# 注册中心展示的名称
instance-id: order1080
# 注册中心实例展示ip地址
prefer-ip-address: true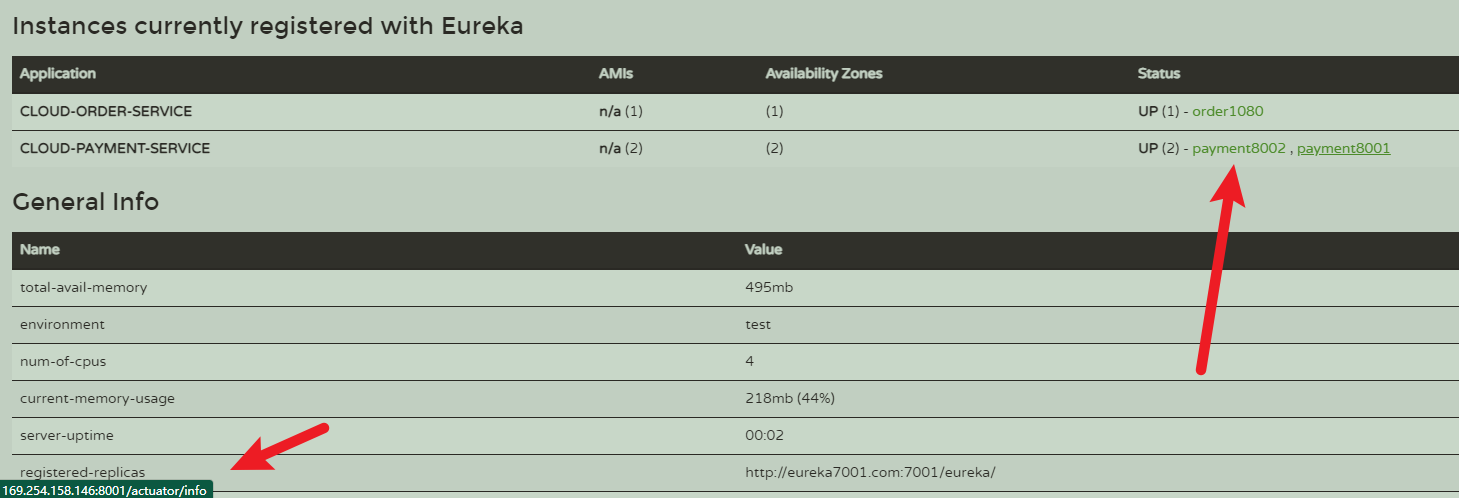
查看注册中心里的服务和实例
@EnableDiscoveryClient
@EnableEurekaClient
@SpringBootApplication
public class OrderMain1080 {
public static void main(String[] args) {
SpringApplication.run(OrderMain1080.class, args);
}
}- @EnableDiscoveryClient
@Slf4j
@RestController()
@RequestMapping("/consumer")
public class OrderController {
public static final String PAYMENT_URL = "http://CLOUD-PAYMENT-SERVICE";
@Resource
private RestTemplate restTemplate;
@Resource
private DiscoveryClient discoveryClient;
@GetMapping("/discovery")
public Object discovery(){
Map<String, Object> result = new HashMap<>();
result.put("services", discoveryClient.getServices());
result.put("instances", discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE"));
return result;
}GET http://localhost:1080/consumer/discovery
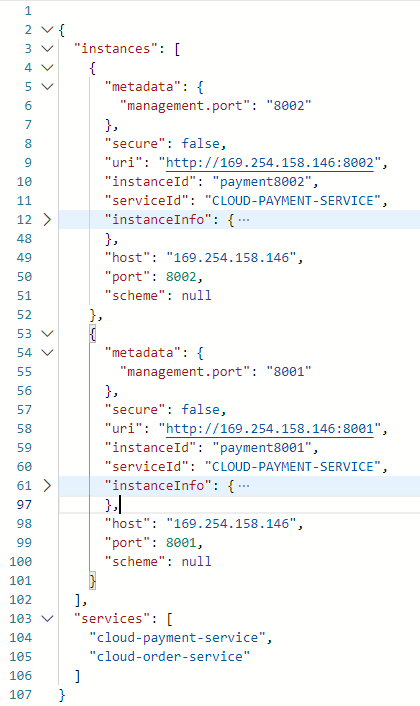
Actuator配置
Eureka 注册中心里点击服务提供者,能查看服务提供者的信息http://localhost:1080/actuator/info
{
"app": {
"name": "cloud-order-service"
},
"company": {
"name": "com.yuyy.springcloud"
},
"build": {
"artifactId": "cloud-consumer-order1080",
"version": "1.0-SNAPSHOT"
}
}配置方法
maven pom
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>application.yml
info:
app:
name: ${spring.application.name}
company:
name: @project.groupId@
build:
artifactId: @project.artifactId@
version: @project.version@关于spring使用maven里的参数,可以看我的这篇文章


分布式 CAP 定理示例: