服务介绍
serverA是一个数据仓库服务,提供数据的版本管理,储存和下载等功能。
线上服务变更大致可分为代码变更、配置变更、数据变更,serverA广泛用于线上数据变更。
由于数据处理对磁盘 IO 性能要求较高(如顺序写入和随机读取),相比网络存储(如Ceph,对象存储等),本地磁盘能提供更低的延迟和更高的吞吐量,因此被选为存储介质。这也使其归属于有状态服务。
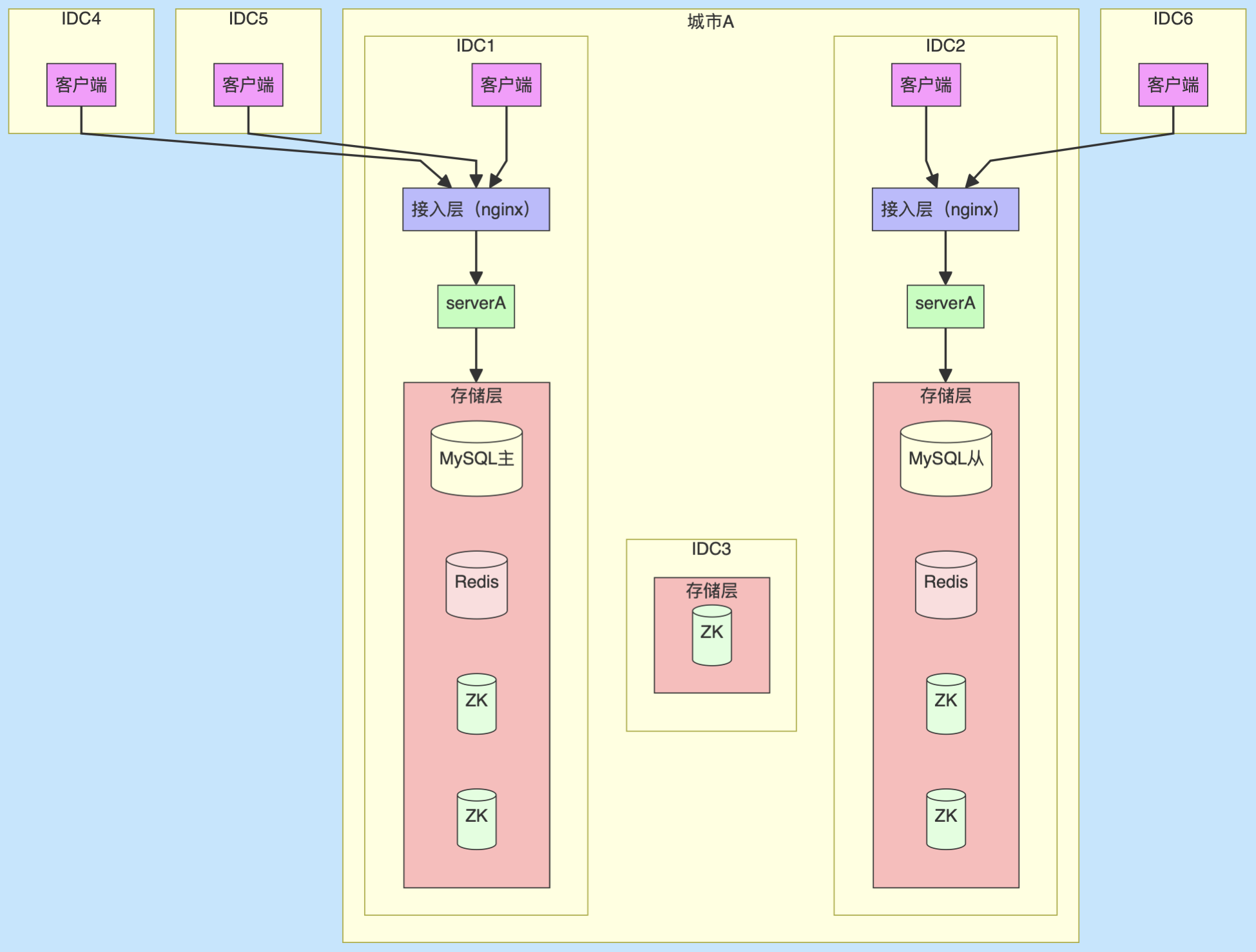
同城双活架构
插个题外话,这里用mermaid画的架构图,推荐大家使用。
mermaid VS PNG
优点
- 可以方便的修改
- 版本管理友好,可以和代码一起放到git仓库。
缺点
- 有门槛,需要掌握专门的语法。
- 这个缺点现在已不是问题,通过AI可以方便的用自然语言画图。
整体来说是利大于弊的。
为什么没有做单元化,实现异地多活?
serverA的业务场景存在跨机房使用,例如IDC1上传的数据,在IDC2进行下载使用,本身就没有机房流量闭环。
如果将用户上传的数据同步到所有IDC,但是实际只有部分IDC使用数据,那么将会浪费大量带宽,磁盘。
存储层双活
存储层会通过同城的网络专线进行数据传输,保证较低的延迟。
Mysql
Mysql 通过主从部署,IDC2 里 serverA 的写流量会通过中间件转发到 IDC1 里的 Mysql 主库。
主从同步通过 binlog 实现,Master 记录写操作日志,Slave 拉取并重放日志,支持异步模式(高性能但有丢失风险)和半同步模式(折中方案,半同步模式要求 Master 收到至少一个 Slave 确认后提交事务,平衡了性能与安全性)。
存在的问题
IDC2 的写入流量需要转发到 IDC1 的主库,因此在 IDC2 的写入 latency 比 IDC1 大。
由于主从同步是异步同步,写入后立即读取从库,可能会读取不到刚才的变更。因此这类强一致性场景下,需要使用 hint 强制主库读。
如何止损
在 IDC1 机房故障的情况下,可通过切主操作,使 IDC2 从库变更为主库,接收读写流量,正常提供服务。业务侧将流量都切到 IDC2 即完成止损。
风险
故障期间可能出现脑裂情况,即 IDC1 和 IDC2 都是主库,如果 IDC1 还有写入流量,在故障恢复后,会丢弃这部分数据,以 IDC2 的主库为准。
Redis
Redis Sentinel 可实现主从自动切换,Redis Cluster 提供分片和高可用,适合容灾场景。
由于跨机房的网络专线存在延迟,导致主从复制存在毫秒级延迟,IDC1里写入的数据,IDC2里不能马上可见。
对于一致性敏感的操作,例如通过redis实现分布式锁,就需要应用层保证单机房闭环。也就是IDC1里的应用加的锁,只有IDC1里使用,IDC2里不会用到。
或者仅仅把Redis当做缓存来使用。
ZK
ZK采用 221 部署(共 5 节点),基于 Paxos 协议,需至少 3 节点存活以维持服务,适合跨 IDC 的高可用场景。IDC1,IDC2,IDC3任意机房挂掉,整个ZK集群依旧可以提供服务。
机房故障下切流
通过 DNS 切流和备用域名,保障了服务在机房故障下的可用性。
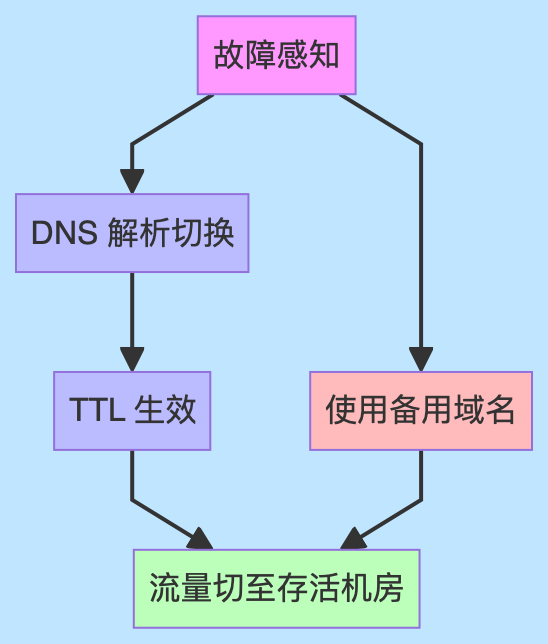
DNS切流
在IDC1或IDC2机房故障的时候,需要操作各个机房的DNS服务,将serverA域名指向故障机房的解析,改为指向存活机房。这个止损动作可以考虑自动化实现,减少人工干预,提升切换效率。
各IDC的域名解析TTL建议设置为60s,避免DNS缓存时间过长,影响切流生效时间。
备用域名
serverA包含了前端,用户在内网通过域名访问。
在IDC1机房故障时,需要通过域名解析平台,将域名切到IDC2。但这强依赖于域名解析平台。
出于稳定性,服务重要性,以及降低RT(故障恢复时间)等因素考虑,可以通过配置备用域名的方式来解决。
新增一个备用域名,解析到IDC2,在IDC1故障时,直接用备用域名访问到前端页面。
基础管控服务建议统一备用域名规范。例如命名,主域名a.b.com,备用域名a-backup.b.com。这样便于故障期间各团队同学能准确使用备用域名进行止损操作。
防腐
上诉操作属于“事中”,对于“事前”来说,我们也要做好 serverA 的流量闭环验证。也就是常态化对 serverA 进行放火,禁止跨机房访问下游服务,模拟机房孤岛情况。验证其他机房故障时,不会影响到 serverA。
数据一致性
IDC之间
用户数据存到serverA,这个动作抽象为一个备份任务。创建备份任务时,同时往ZK里的两个队列写入任务。IDC1内的serverA从队列1里消费备份任务,IDC2内的serverA从队列2里消费备份任务。达到最终一致性效果。
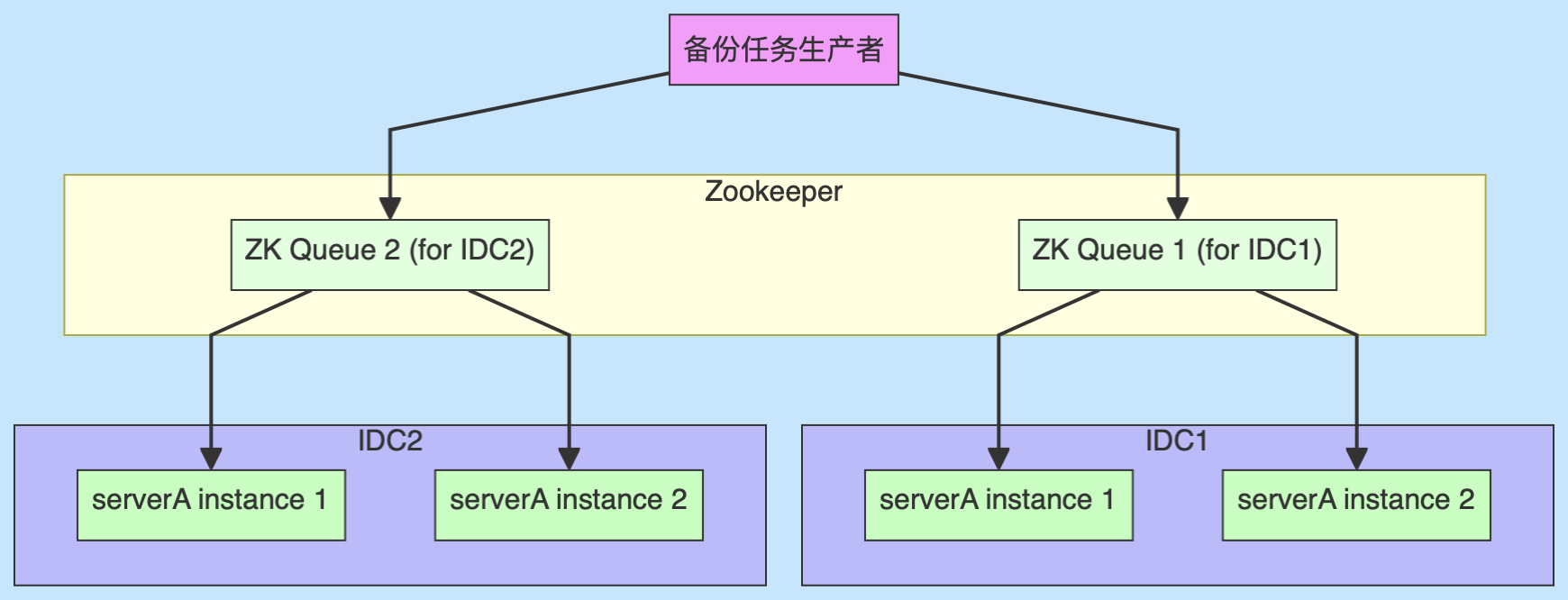
在数据不一致的时间窗口内,serverA是否对外提供服务,取决于控制面服务内相应的开关。满足不同用户对于机房之间数据不一致的不同要求。
IDC内
IDC内会部署2各实例,实现高可用。在消费备份任务时,会先抢zk里的分布式锁。拿到锁的实例执行备份任务。同时两个实例之间通过nfs互挂彼此的数据目录。serverA在备份数据时,会将数据同时写入到自己的数据目录和peer的nfs挂载路径。
存在的问题
架构扩展性差,IDC内只能部署两个实例。不过nfs互挂稳定性很好,没出过什么事故,用不着改造。
但后面随着业务的发展,数仓的数据越来越多,流量也越来越大。IDC内两个实例,在高峰期时,带宽被打满,架构问题迫在眉睫。
新架构
针对 v1 架构的扩展性和双写耦合问题,v2 架构进行了如下改进。
zk里的备份任务队列,不再是两个队列(部署serverA的IDC各一个队列),而是每个serverA实例一个队列,独立消费。IDC内,可以水平扩展多个serverA实例,各自消费自己队列里的任务。
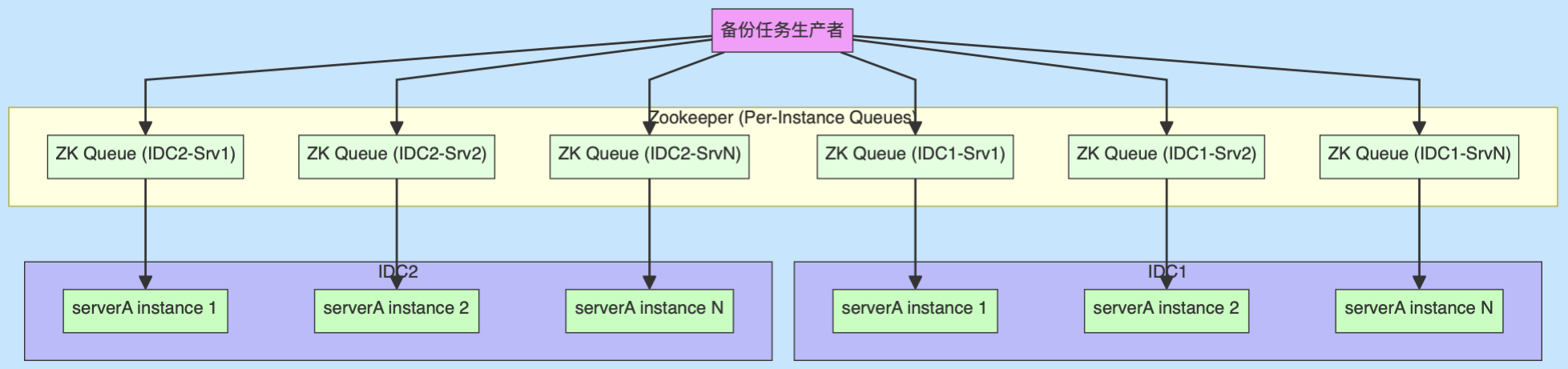
每个serverA实例执行完成备份任务后,状态写入 DB 后,客户端可动态选择可用实例下载数据,避免了 v1 双写失败导致的服务不可用问题,且吞吐量提升可达数倍(视实例数而定)。