本文最后更新于 1580 天前,其中的信息可能已经有所发展或是发生改变。
Job
背景问题
- 我们如何保证 Pod 内进程正确的结束?
- 如何保证进程运行失败后重试?
- 如何管理多个任务,且任务之间有依赖关系?
- 如何并行地运行任务,并管理任务的队列大小?
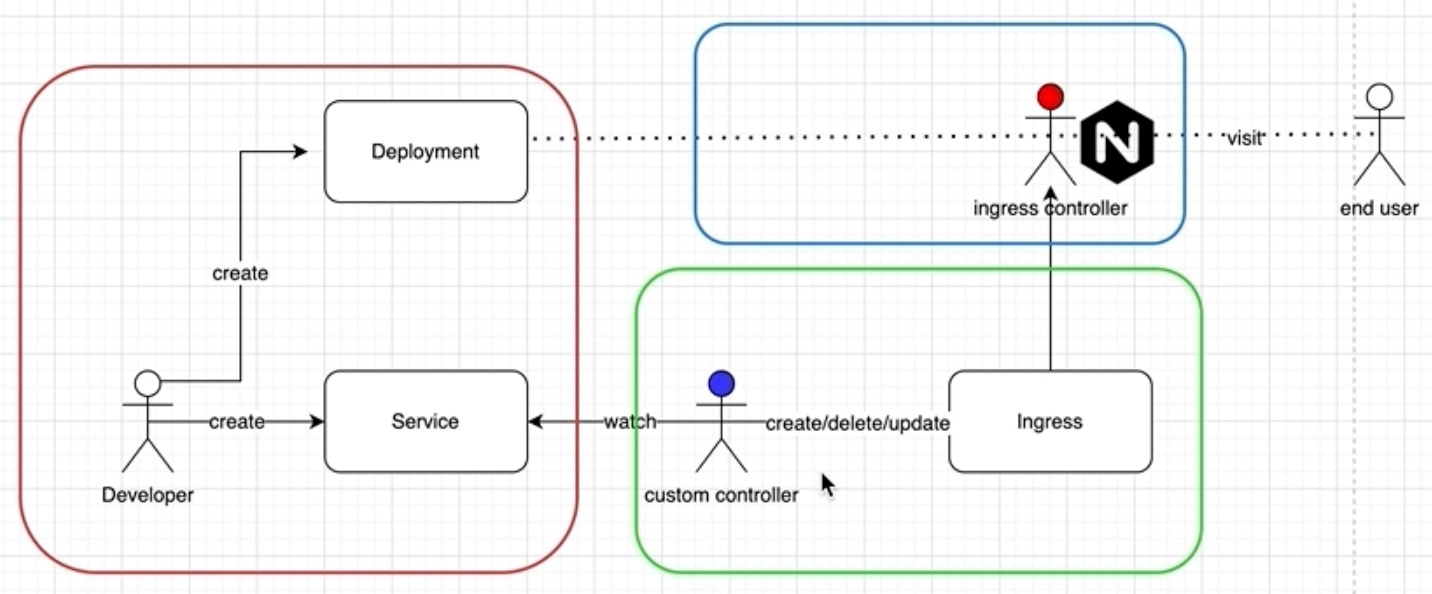
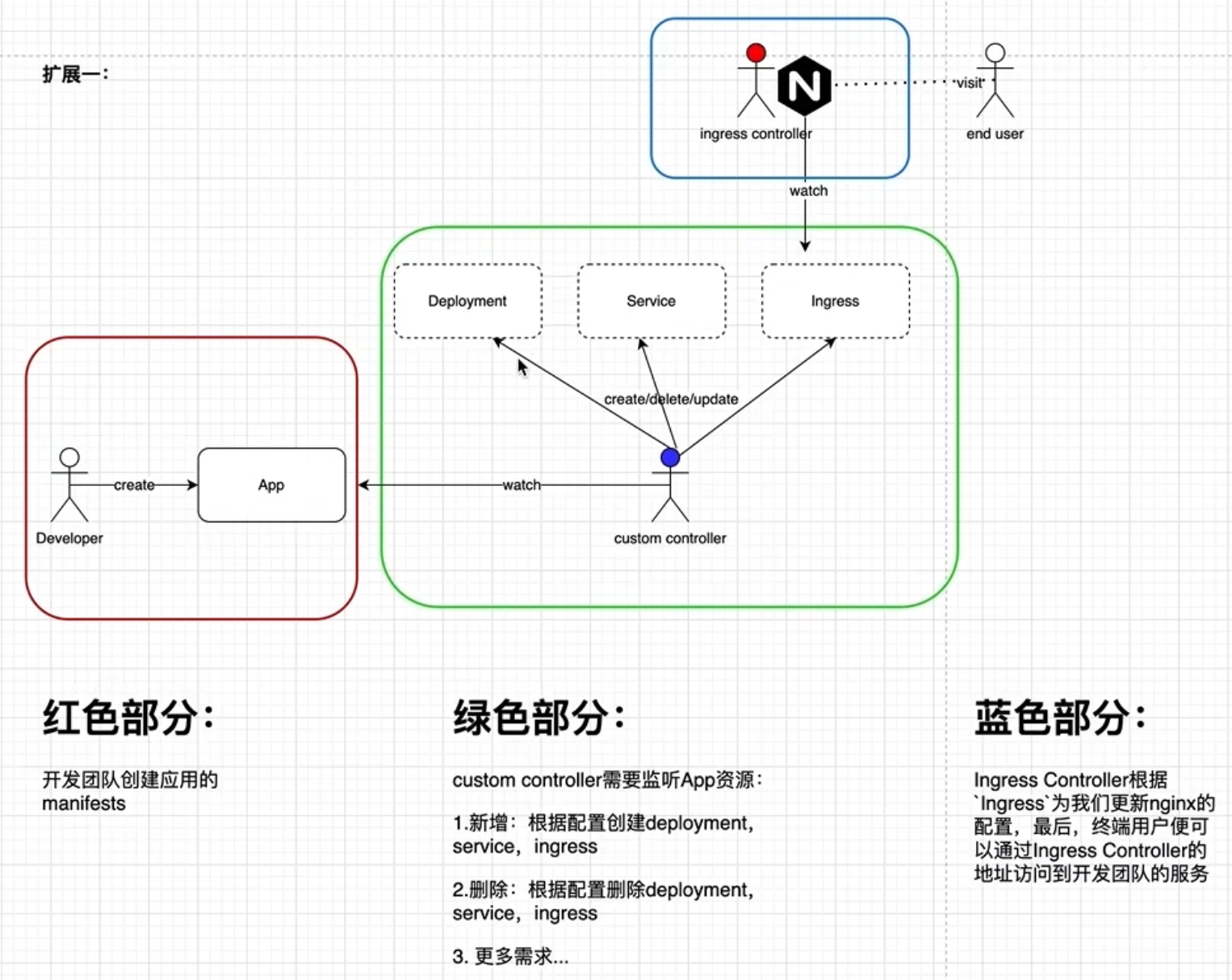
Job:管理任务的控制器
-
Job 可以创建指定数量的 Pod ,并监控它是否成功地运行或终止
-
可以根据 Pod 的状态来给 Job 设置重置的方式及重试的次数
为什么要根据 pod 的状态
-
根据依赖关系,保证上一个任务运行完成之后再运行下一个任务
-
控制任务的并行量
Job 语法

- restartPolicy:重试策略
- Never:不重试
- OnFailure:失败的时候重试
- Always:成功与否都重试
- backoffLimit:重试次数限制
- completions:job 运行总次数
- parallelism:并发数
查看 Job 状态
命令:kubectl get job

- duration:job运行时长
- age:pod创建多久了
Cronjob 语法
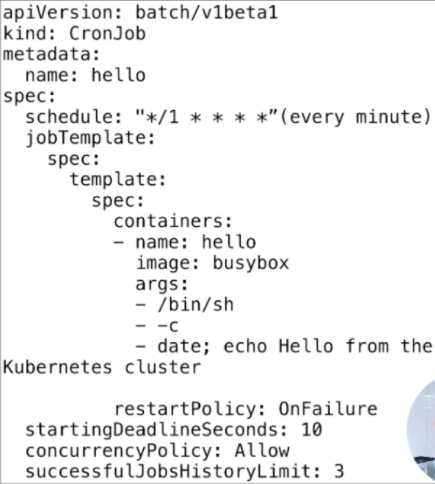
- startingDeadlineSeconds:job 等待启动的时间限制
- concurrencyPolicy:是否允许并行运行
- JobsHistoryLimit:每一次 CronJob 运行完之后,都会遗留上一个 Job 的运行历史、查看时间。这个参数就是对保留的历史信息的数量限制
Job Controller
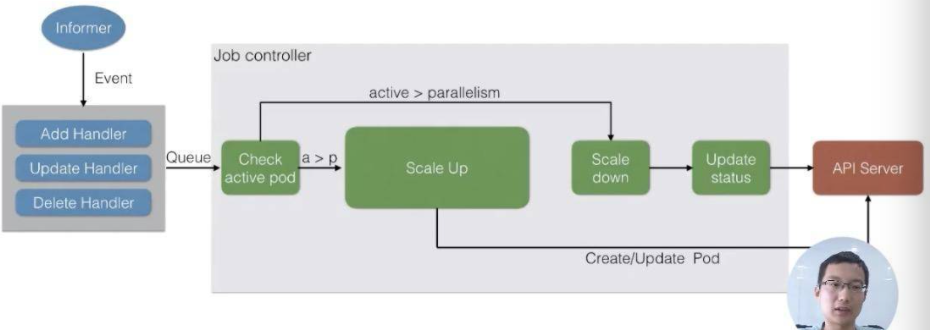
- check active pod:比较当前运行的 pod 和配置的并发数
DaemonSet
背景问题
- 首先如果希望每个节点都运行同样一个 pod 怎么办?
- 如果新节点加入集群的时候,想要立刻感知到它,然后去部署一个 pod,帮助我们初始化一些东西,这个需求如何做?
- 如果有节点退出的时候,希望对应的 pod 会被删除掉,应该怎么操作?
- 如果 pod 状态异常的时候,我们需要及时地监控这个节点异常,然后做一些监控或者汇报的一些动作,那么这些东西运用什么控制器来做?
DaemonSet:守护进程控制器
- 保证集群内的每一个节点都运行一组相同的 pod;
- 同时还能根据节点的状态保证新加入的节点自动创建对应的 pod;
- 在移除节点的时候,能删除对应的 pod;
- 而且它会跟踪每个 pod 的状态,当这个 pod 出现异常、Crash(崩溃) 掉了,会及时地去 recovery 这个状态。
编排文件

-
和 deployment 差不多,类型不一样罢了
使用场景
- 存储,GlusterFS 或者 Ceph 之类的东西,需要每台节点上都运行一个类似于 Agent 的东西
- 日志收集,比如说 logstash 或者 fluentd
- 监控,每个节点被监控的数据需要往 Promethues 里存
查看 DaemonSet 状态
kubectl get DaemonSet(DaemonSet 可缩写为 ds)

- desired:需要的 pod 个数
- up-to-date:最新创建的个数
- NODE SELECTOR:在 DaemonSet 里面非常有用。有时候我们可能希望只有部分节点去运行这个 pod 而不是所有的节点,所以有些节点上被打了标签的话,DaemonSet 就只运行在这些节点上。
更新 DaemonSet
更新策略
- RollingUpdate:滚动更新
- OnDelete:pod 被删除后才会被更新,不会主动中断
DaemonSet Controller
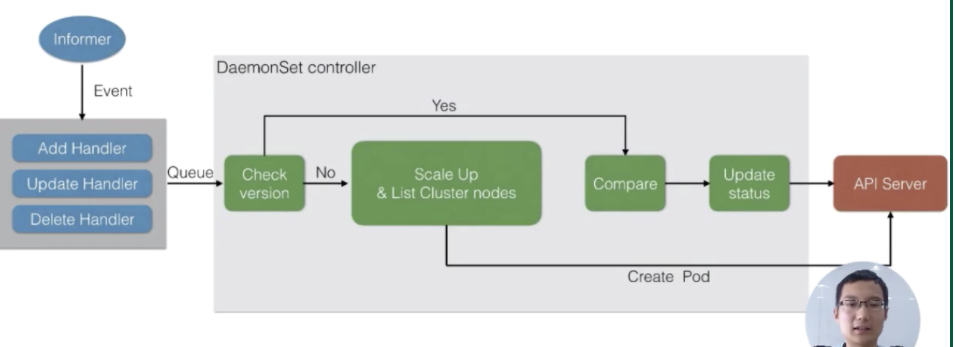
- 监听 node 事件
其他
- 前面提到的 yaml 文件,应该称为编排文件
- 查看 pod 日志:
kubectl logs pod <podname> - CronJob 主要是用来运作一些清理任务或者说执行一些定时任务,比如说 Jenkins 构建