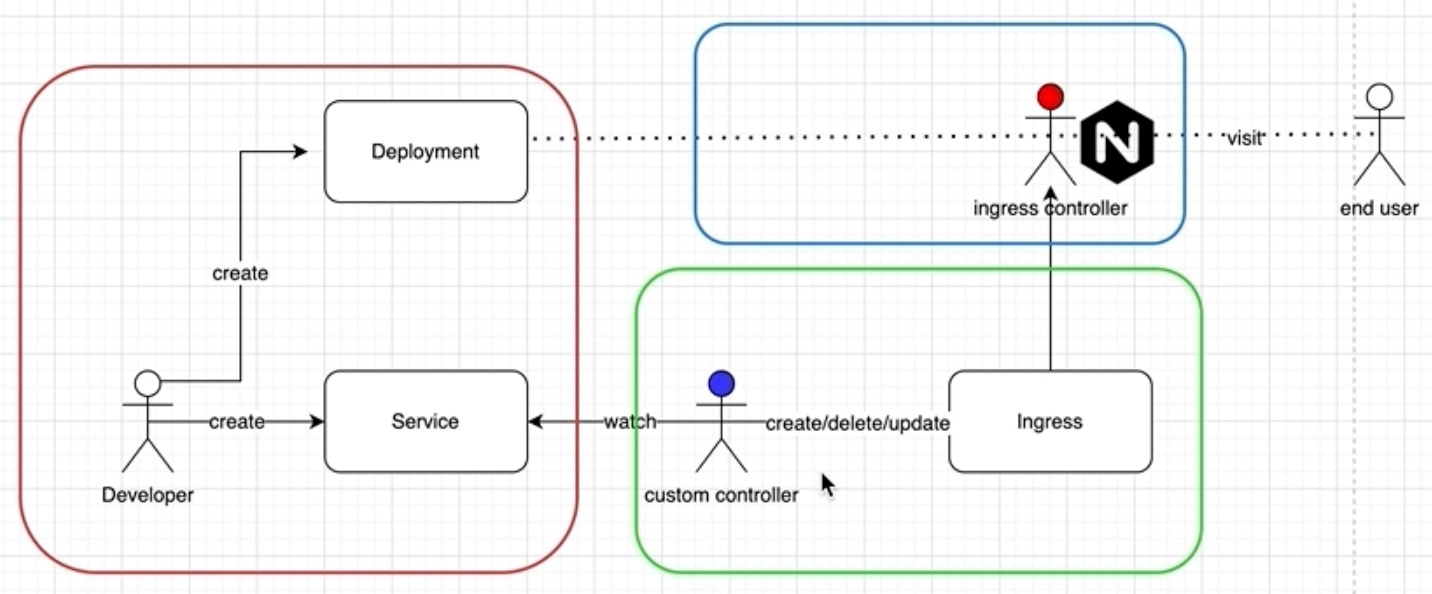
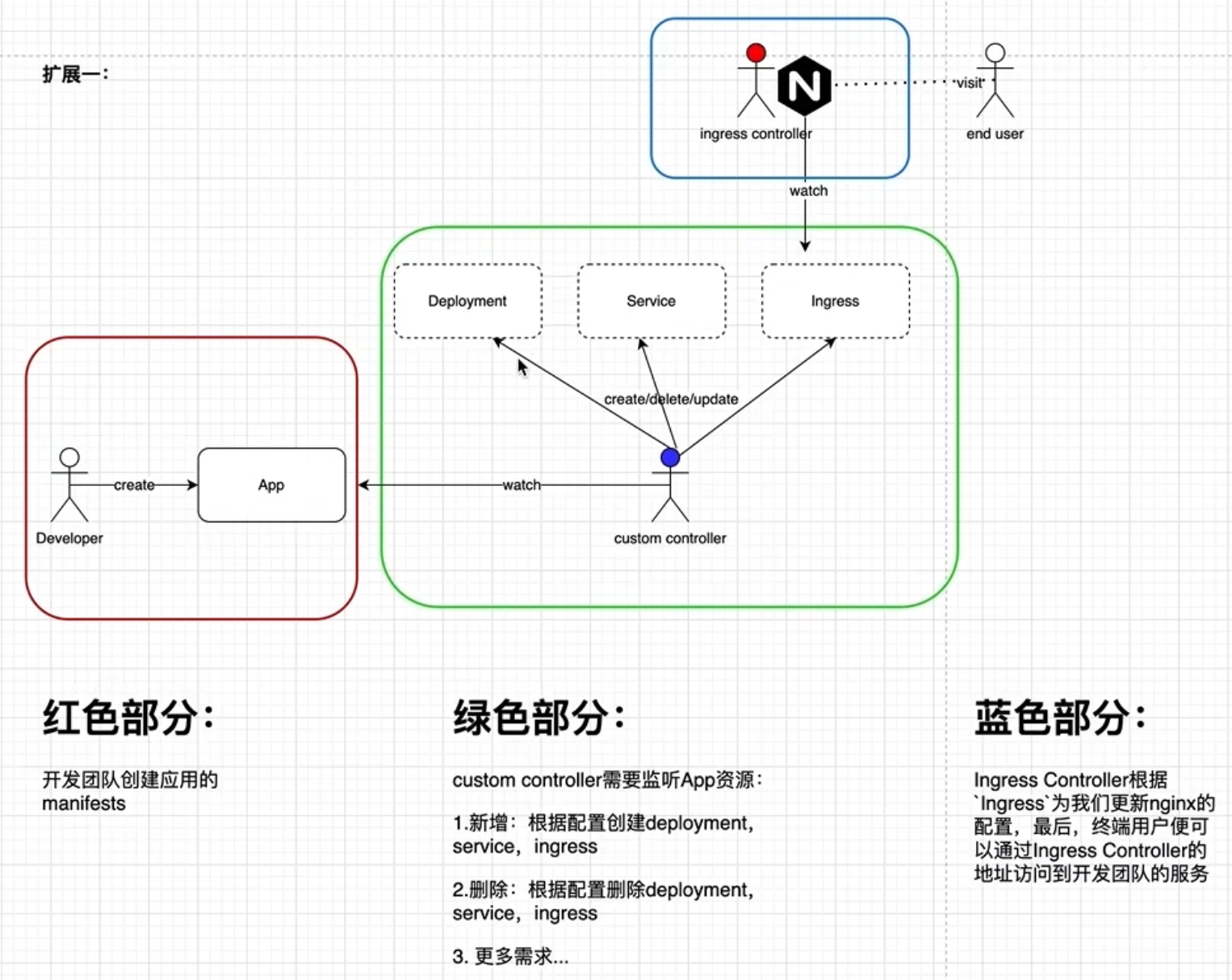
client-go 架构图
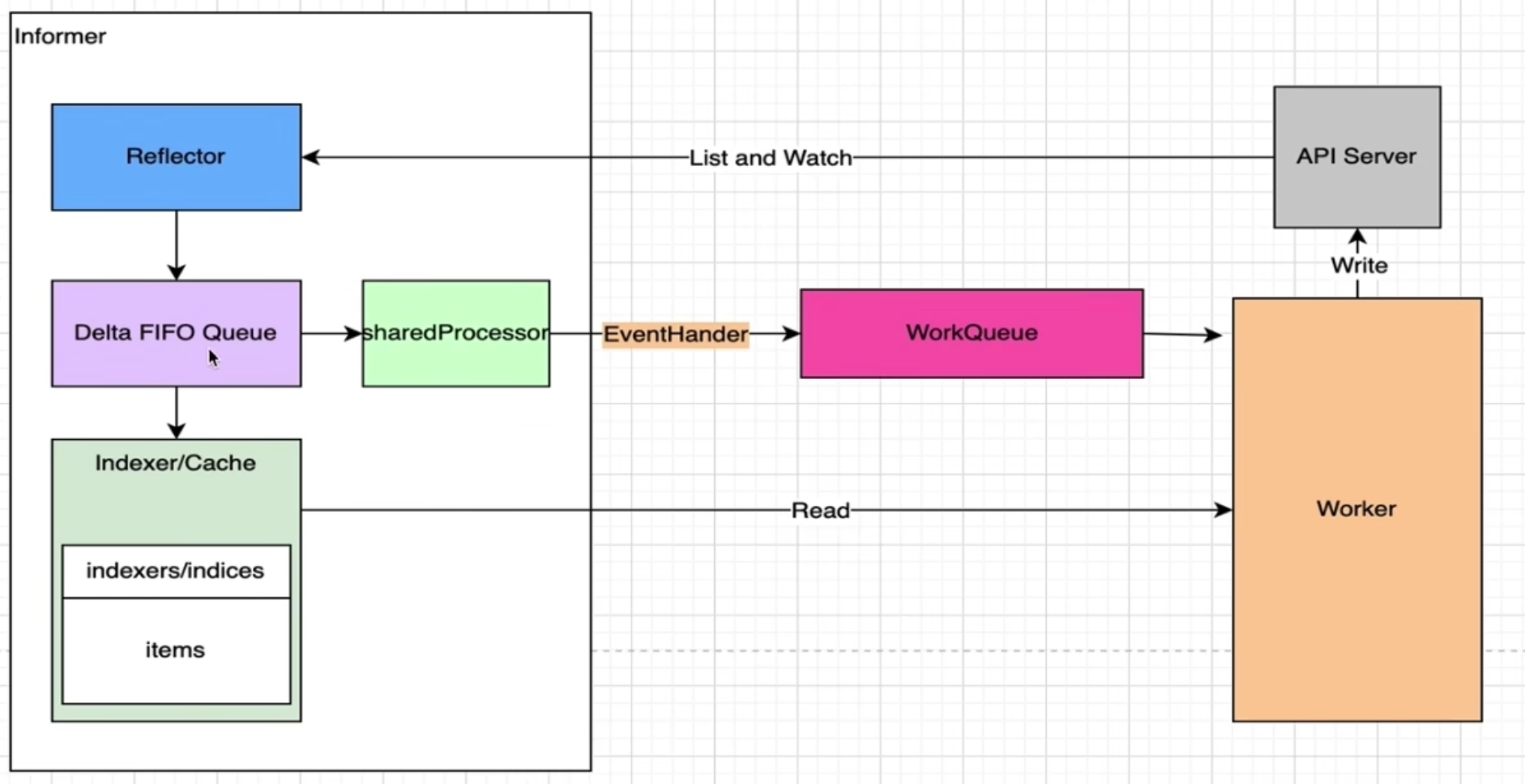
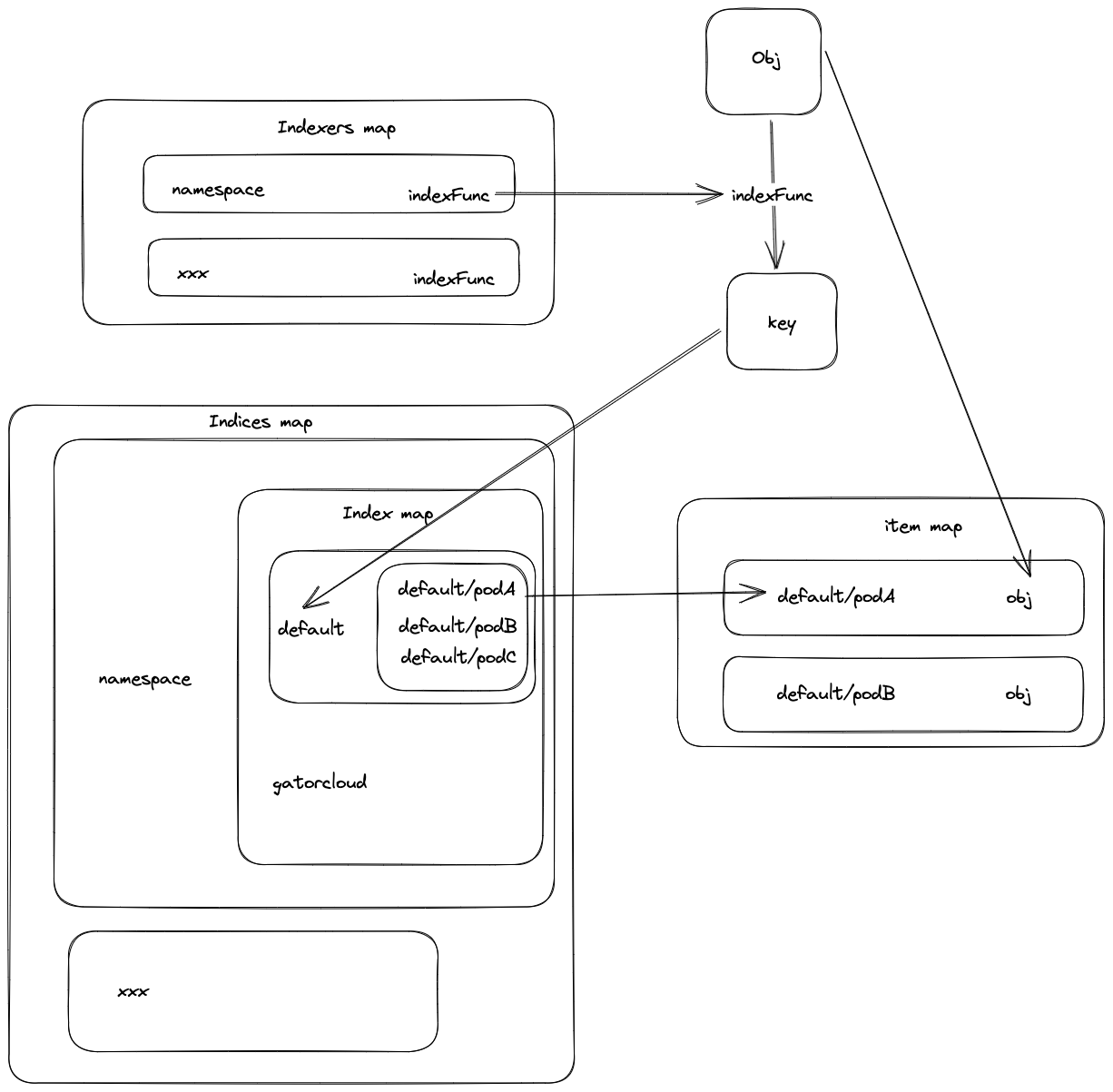
Indexer原理
-
Indexer缓存k8s资源对象,并提供便捷的方式查询。例如获取某个namespace下的所有资源
-
indexer接口继承了store接口,所以indexer的实现类也是store的实现类。add方法被调用的地方和store一样,是reflector调用的。
type Indexer interface { Store // Index returns the stored objects whose set of indexed values // intersects the set of indexed values of the given object, for // the named index Index(indexName string, obj interface{}) ([]interface{}, error) // IndexKeys returns the storage keys of the stored objects whose // set of indexed values for the named index includes the given // indexed value IndexKeys(indexName, indexedValue string) ([]string, error) // ListIndexFuncValues returns all the indexed values of the given index ListIndexFuncValues(indexName string) []string // ByIndex returns the stored objects whose set of indexed values // for the named index includes the given indexed value ByIndex(indexName, indexedValue string) ([]interface{}, error) // GetIndexers return the indexers GetIndexers() Indexers // AddIndexers adds more indexers to this store. If you call this after you already have data // in the store, the results are undefined. AddIndexers(newIndexers Indexers) error } -
从目前阅读的源码来看,indexer 的实现类和delta fifo都是store的实现类,add方法都是在同一个地方调用的,那么它们应该是平级关系,而不是前一篇文章里的结构图所示,indexer是delta fifo调用的。todo:后面了解更多后再来解答这个问题
-
add方法被多个函数调用,并不是在同一个地方调用的。
-
从 delta 队列 pop 得到资源对象,会调用sharedIndexInformer的HandleDeltas函数,然后调用processDeltas函数,在这里会先将事件对象存到 indexer 里,然后调用sharedIndexInformer的OnAdd函数进行事件处理。整个流程确实和上面的流程图一致。
func processDeltas( // Object which receives event notifications from the given deltas handler ResourceEventHandler, clientState Store, deltas Deltas, isInInitialList bool, ) error { // from oldest to newest for _, d := range deltas { obj := d.Object switch d.Type { case Sync, Replaced, Added, Updated: if old, exists, err := clientState.Get(obj); err == nil && exists { if err := clientState.Update(obj); err != nil { return err } handler.OnUpdate(old, obj) } else { if err := clientState.Add(obj); err != nil { return err } handler.OnAdd(obj, isInInitialList) } case Deleted: if err := clientState.Delete(obj); err != nil { return err } handler.OnDelete(obj) } } return nil }
-
-
indexer如何保存数据?
-
主要涉及以下的数据结构
type threadSafeMap struct { lock sync.RWMutex // 保存k8s资源对象 items map[string]interface{} // index implements the indexing functionality index *storeIndex } type storeIndex struct { // indexers maps a name to an IndexFunc indexers Indexers // indices maps a name to an Index indices Indices } // key是IndexFunc计t草出来的结果,比如default,valve是所有obj的key的集合 type Index map[string]sets.String // key是素引/的分类名,比如namespace type Indices map[string]Index // key是素引/的分类名, 比如namespace,value是一个方法,通过读方法可以获取obj的namespace, 比ttldefault type Indexers map[string]IndexFunc type IndexFunc func(obj interface{}) ([]string, error) // IndexFunc举例 func MetaNamespaceIndexFunc(obj interface{}) ([]string, error) { meta, err := meta.Accessor(obj) if err != nil { return []string{""}, fmt.Errorf("object has no meta: %v", err) } return []string{meta.GetNamespace()}, nil } -
由于命名太相似,容易混淆,通过画图才理清楚它们的关系

-
更新删除时都会通过
updateIndices维护上诉数据结构func (c *threadSafeMap) Update(key string, obj interface{}) { c.lock.Lock() defer c.lock.Unlock() oldObject := c.items[key] c.items[key] = obj c.index.updateIndices(oldObject, obj, key) } func (c *threadSafeMap) Delete(key string) { c.lock.Lock() defer c.lock.Unlock() if obj, exists := c.items[key]; exists { c.index.updateIndices(obj, nil, key) delete(c.items, key) } }
-
-
SharedInformer原理
Sharelnformer的作用
主要负责完成两大类功能:
-
缓存我们关注的资源对象的最新状态的数据
eg.创建Indexer/Clientset(通过listerwatcher)/DeltaFIFO/Controller(包含Reflector的创建) -
根据资源对象的变化事件来通知我们注册的事件处理方法
eg.创建sharedProcessor/,注册事件处理方法
Sharelnformer的创建
-
NewSharedIndexlnformer
创建Informer的基本方法
-
NewDeploymentInformer
创建内建资源对象对应的Informer的方法,调用NewSharedIndexlnformer:实现 -
NewSharedInformerFactory
工厂方法,内部有一个map存放我们创建过的Informer,达到共享informer的目的,避免重复创建informer对象。informer包含indexer,缓存资源对象,重复创建会导致浪费内存
为什么client-go大量用到了锁?
平时写业务代码,大部分对象都是临时的,或者是不包含共享变量的单例对象,基本不存在并发问题。而client-go里创建的很多对象都是共享变量,有的用于缓存数据,为了复用共享一份数据,所以会存在数据竞争问题
创建informer
func main() {
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)
if err != nil {
panic(err)
}
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
factory := informers.NewSharedInformerFactoryWithOptions(clientset, 0, informers.WithNamespace("default"))
informer := factory.Core().V1().Pods().Informer()
_, err = informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
fmt.Println("add")
},
UpdateFunc: func(obj interface{}, new interface{}) {
fmt.Println("update")
},
DeleteFunc: func(obj interface{}) {
fmt.Println("delete")
},
})
stop := make(chan struct{})
factory.Start(stop)
// factory.WaitForCacheSync(stop)
<-stop
}- 数据来源是reflector的listAndWatch
- 内部创建delta fifo,但没看到使用
和delta fifo的区别
虽然都能根据reflector的listAndWatch得到资源变化,并执行自定义事件。但是delta fifo有队列缓冲,并且还能对事件进行去重。而informer只是执行注册的事件。
sharedInformer内部调用的就是deltaFifo。
WorkQueue原理
为了解决informer监听的事件产生速度,和事件的消费速度不匹配,于是在其中加入了缓冲队列。
队列接口
type Interface interface {
Add(item interface{})
Len() int
Get() (item interface{}, shutdown bool)
Done(item interface{})
ShutDown()
ShutDownWithDrain()
ShuttingDown() bool
}
通用队列实现
type Type struct {
// 待处理的任务
queue []t
// 待处理的任务(用于去重)
dirty set
// 处理中的任务
processing set
cond *sync.Cond
shuttingDown bool
drain bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.WithTicker
}为什么需要3个数据结构,而不是一个queue?
- 首先需要任务队列实现去重,就得加个set
- 多个消费者并行消费queue里的任务时,会存在多个任务同时处于处理中,如果想查询哪些任务在处理中的状态下,就得将这些任务存在一个集合里。在Add方法中用于区别哪些是需要重试的任务。
重试任务
在处理任务期间,调用了add方法,再调用Done,就会重试任务。
func (q *Type) Add(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
if q.shuttingDown {
return
}
if q.dirty.has(item) {
return
}
q.metrics.add(item)
// 需要重试的任务加到了dirty,但没有立即加入到queue
q.dirty.insert(item)
if q.processing.has(item) {
return
}
q.queue = append(q.queue, item)
q.cond.Signal()
}func (q *Type) Done(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
q.metrics.done(item)
q.processing.delete(item)
// 只有调用了Done方法,才会讲待重试的任务放进queue
if q.dirty.has(item) {
q.queue = append(q.queue, item)
q.cond.Signal()
} else if q.processing.len() == 0 {
q.cond.Signal()
}
}为什么不在Add方法中,直接将重试的任务加到queue,而是在Done方法中添加?
这样存在的问题是,如果另一个消费者立即来消费这个任务,就会导致同一时间有两个消费者消费同一个任务。
延迟队列实现
type DelayingInterface interface {
Interface
AddAfter(item interface{}, duration time.Duration)
}- 在通用队列的基础上增加了延迟执行的方法
- 延迟执行使用比较多的是时间轮算法,这里是简单实现:轮询最小堆获取时间最靠前的任务,根据当前时间判断是否立即执行
具体延迟逻辑
func (q *delayingType) waitingLoop() {
defer utilruntime.HandleCrash()
// Make a placeholder channel to use when there are no items in our list
never := make(<-chan time.Time)
// Make a timer that expires when the item at the head of the waiting queue is ready
var nextReadyAtTimer clock.Timer
waitingForQueue := &waitForPriorityQueue{}
heap.Init(waitingForQueue)
// 用于添加任务时,判断任务是否存在,如果存在,并且新任务的时间提前了,那么就更新任务
waitingEntryByData := map[t]*waitFor{}
for {
if q.Interface.ShuttingDown() {
return
}
now := q.clock.Now()
// Add ready entries
for waitingForQueue.Len() > 0 {
entry := waitingForQueue.Peek().(*waitFor)
// 时间未到
if entry.readyAt.After(now) {
break
}
// 时间到了就取出并加入任务队列执行
entry = heap.Pop(waitingForQueue).(*waitFor)
q.Add(entry.data)
delete(waitingEntryByData, entry.data)
}
// Set up a wait for the first item's readyAt (if one exists)
nextReadyAt := never
if waitingForQueue.Len() > 0 {
if nextReadyAtTimer != nil {
nextReadyAtTimer.Stop()
}
entry := waitingForQueue.Peek().(*waitFor)
nextReadyAtTimer = q.clock.NewTimer(entry.readyAt.Sub(now))
nextReadyAt = nextReadyAtTimer.C()
}
select {
case <-q.stopCh:
return
case <-q.heartbeat.C():
// continue the loop, which will add ready items
case <-nextReadyAt:
// continue the loop, which will add ready items
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) {
// 时间未到
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
// 时间到了,以前的重复任务怎么处理?
q.Add(waitEntry.data)
}
drained := false
for !drained {
select {
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) {
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
q.Add(waitEntry.data)
}
default:
drained = true
}
}
}
}
}- 循环从堆里取任务,如果时间到了就执行,没到就阻塞,等待期望的时间
- 阻塞期间,如果有任务到来,会打断阻塞,根据当前时间判断新任务是立即执行还是添加到堆
- 由于堆变化了,最早执行的任务可能改变,需要重新进行第一步
我认为存在的问题
- 如果更改任务执行时间,重新添加进延迟队列,并且任务新的执行时间的时间到了,那么会立即添加到任务队列。但是延迟队列里的旧任务(执行时间不同,任务相同)没有清除,依旧会执行。
- 当新任务到达waitingForAddCh时,消费一个任务后会循环消费waitingForAddCh里的全部任务,感觉这个优化意义不大,因为外部循环并没有什么耗时操作,仅仅是从堆里peek一个任务,并根据该任务的执行时间创建timer进行阻塞(select同时监听了waitingForAddCh,如果有新任务也不会阻塞)
限速队列实现
type RateLimitingInterface interface {
DelayingInterface // 延时队列里包含了普通队列,限速队列里包含了延时队列
AddRateLimited(item interface {})
Forget (item interface {}) // 停止元素重试
NumRequeues (item ihterface {}) int // 记录这个元素被处理多少次了
}原理
func (q *rateLimitingType) AddRateLimited(item interface{}) {
q.DelayingInterface.AddAfter(item, q.rateLimiter.When(item))
}- 通过限流算法计算需要延迟多久执行,并提交到延迟队列
使用
queue := workqueue.NewRateLimitingQueueWithConfig(workqueue.DefaultControllerRateLimiter(), workqueue.RateLimitingQueueConfig{Name: "my-queue"})
_, err = informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
fmt.Println("add")
key, err := cache.MetaNamespaceKeyFunc(obj)
if err != nil {
panic(err)
}
queue.AddRateLimited(key)
},
UpdateFunc: func(obj interface{}, new interface{}) {
fmt.Println("update")
key, err := cache.MetaNamespaceKeyFunc(new)
if err != nil {
panic(err)
}
queue.AddRateLimited(key)
},
DeleteFunc: func(obj interface{}) {
fmt.Println("delete")
key, err := cache.MetaNamespaceKeyFunc(obj)
if err != nil {
panic(err)
}
queue.AddRateLimited(key)
},
})- 加入到队列里的只是对象key,到了消费这个对象时,会根据key从indexer里获取
- 没有区分创建还是更新,因为controller的原理是,根据期望状态,循环调整当前状态,直到当前状态等于期望状态。所以只需要将期望状态存入队列就行。