本文最后更新于 1144 天前,其中的信息可能已经有所发展或是发生改变。
分布式缓存
01 业务数据访问性能太低怎么办?
缓存的定义
狭义缓存
加速CPU数据交换的存储器。
广义缓存
数据高速交换的存储介质,加速数据访问。
缓存成本
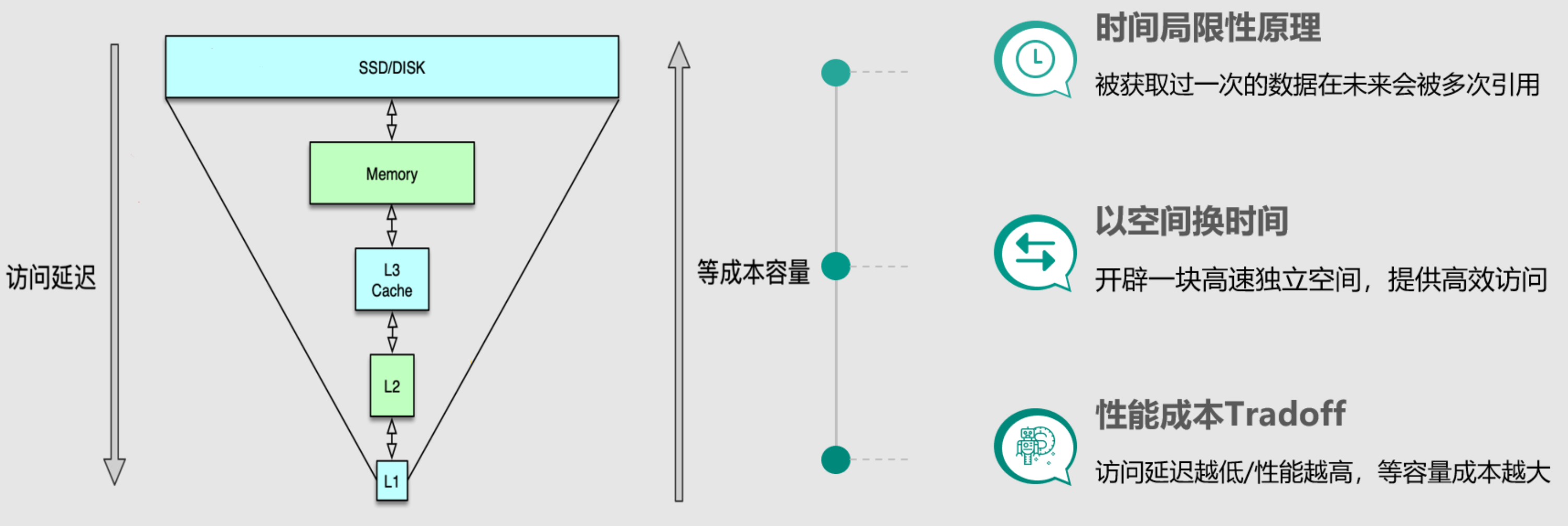
- 时间局限性原理,即被获取过一次的数据在未来会被多次引用,比如一条微博被一个人感兴趣并阅读后,它大概率还会被更多人阅读。
- 以空间换时间,因为原始数据获取太慢,所以我们开辟一块高速独立空间,提供高效访问,来达到数据获取加速的目的。另外可以节约流量,降低负载。缓存中存储的往往是需要频繁访问的中间数据甚至最终结果,这些数据相比DB中的原始数据小很多,这样就可以减少网络流量,降低网络拥堵,同时由于减少了解析和计算,调用方和存储服务的负载也可以大幅降低。
- 性能成本Tradeoff,在系统架构设计时,你需要在系统性能和开发运行成本之间做取舍。相同成本的容量,SSD硬盘容量会比内存大10~30倍以上,但读写延迟却高50~100倍。
缓存的优势
- 提升访问性能
- MySQL单实例的读写QPS通常只有千级别(3000~6000),读写平均耗时10~100ms级别(超过200ms可被定义为慢SQL),如果一个用户请求需要查20个不同的数据来聚合,仅仅DB请求就需要数百毫秒甚至数秒。而cache的读写性能正好可以弥补DB的不足,比如Memcached的读写QPS可以达到10~100万 级别,读写平均耗时在1ms以下,结合并发访问技术,单个请求即便查上百条数据,也可以轻松应对。
- 降低网络拥堵
- 减轻服务负载
- 增强可扩展性
- 缓存也可以弹性伸缩
缓存的代价
任何事情都有两面性,缓存也不例外。
- 服务系统中引入缓存,会增加系统的复杂度。
- 由于缓存相比原始DB存储的成本更高。
- 由于一份数据同时存在缓存和DB中,甚至缓存内部也会有多个数据副本,多份数据就会存在一致性问题,同时缓存体系本身也会存在可用性问题和分区的问题。
参考
02 如何根据业务来选择缓存模式和组件?
业务系统读写缓存主要有 3 种模式
- Cache Aside(旁路缓存)
- Read/Write Through(读写穿透)
- Write Behind Caching(异步缓存写入)
Cache Aside
常见、简单的一种模式
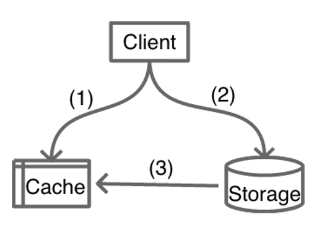
Read
miss后读db+回写
Write
更新db,删除cache。
特点
Lazy计算,以DB数据为准
适合场景
- 更强一致性
- Cache数据构建复杂
- 缓存数据更新复杂
优化
如果缓存加载过程复杂,懒加载会影响用户,可以增加一个watch DB 日志的服务,更新DB后,异步创建缓存。但是这期间的查询操作,还是要自行创建缓存。异步创建缓存还可以进行预读,缓存附近的内容,空间局限性原理。也可以通过MQ来做。(Go 进阶训练营 – 评论系统架构设计二:详细设计)
分析下一致性问题
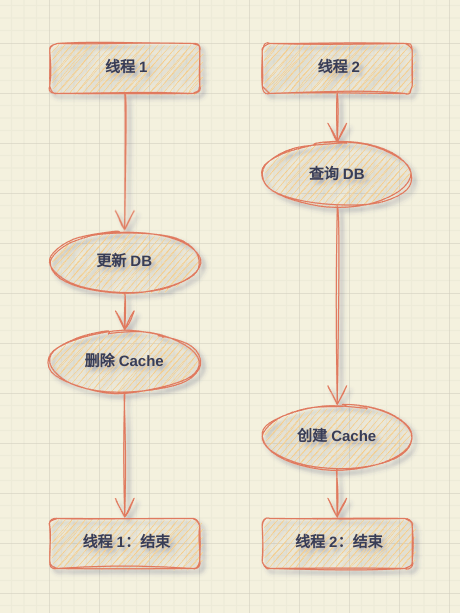
- 如果创建Cache过程简单,写Cache的耗时一般比更新DB+删除Cache耗时短,那么可以大幅降低 cache 和 DB 中数据不一致的概率。
- 如果创建Cache过程复杂,耗时,那么就需要考虑在创建缓存的时候注意并发问题,例如使用CAS(Redis的watch)。
- 实际运用时,还需要考虑删除缓存失败、更新DB失败的情况。
- 开启DB事务
- 写入DB
- 删除缓存
- 提交DB事务
- 这样就能解决上诉异常情况,但是这样增加了缓存不一致的概率,可使用延迟双删进行优化。
Read/Write Through
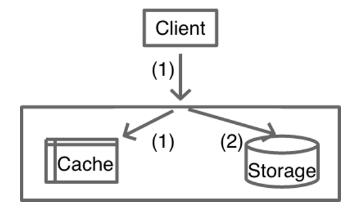
Write
cache不存在更新DB,cache存在更新cache+DB
Read
cache miss后由缓存服务加载并写cache
特点
-
存储服务负责操作缓存,业务应用端代码只用关注业务逻辑本身,系统隔离型更佳。
-
热数据友好,写操作时更新缓存,而不是删除缓存。
适合场景
- 数据有冷热区分,例如冷门用户发表微博,保存数据时,判断缓存中是否有该用户微博数据,有的话就是热数据,则更新缓存+DB;没有的话就是冷数据,直接写DB。主要还是对热数据友好。
- 重新创建缓存困难,采用更新更合适。
Write Behind Caching
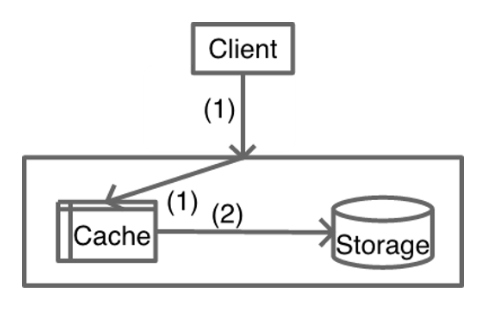
Write
只更新缓存,缓存服务异步更新DB
Read
miss后由缓存服务加载+写cache
特点
-
写性能最高,定期异步刷新
- Linux Page Cache 思想类似,通过将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,提高性能。写文件时,只写到缓存,不会立即写磁盘,通过内核线程定时同步写到磁盘(Write back)。
-
存在数据丢失概率。
-
与 Read/Write Through 模式类似,也由数据存储服务来管理 cache 和 DB 的读写。
适合场景
-
数据存储的写性能最高,非常适合一些变更特别频繁,但对一致性要求不太高
-
可以合并写请求的业务,比如对一些计数业务,一条微博被点赞 1万 次,如果更新 1万 次 DB 代价很大,而合并成一次请求直接加 1万,则是一个非常轻量的操作。
- 和Redis的AOF重写是一个思想。
总结
三种模式各有优劣,不存在最佳模式。实际上,我们也不可能设计出一个最佳的完美模式出来,如同前面讲到的空间换时间、访问延迟换低成本一样,高性能和强一致性从来都是有冲突的,系统设计从来就是取舍,随处需要 trade-off。根据业务场景,更好的做 trade-off,从而设计出更好的服务系统。