同系列文章:Go 进阶训练营
服务调用:gRPC
什么是gRPC?
- A high-performance, open-source universal RPC framework。
- 语言中立,公司里可能存在不同语言的服务需要交互。
- 统一采用gRPC作为服务之间的通信协议,可能存在其他性能更好的解决方案,但不要过早关注性能问题,先标准化更重要。
- 轻量级、高性能,序列化比JSON性能好
- 可插拔,支持插件,例如gRPCGetway插件可以生成http接口,默认只生成gRPC接口。协议可插拔,支持JSON、xml等。
- IDL:代码即文档,避免接口文档未更新的情况。
- 快速生成接口服务端、客户端代码,服务端已定义好接口,自己实现下就行。
- 移动端:基于标准的 HTTP2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量。
- 数据库连接池产生的原因是协议设计缺陷,具体参照下面的http协议演进
- 负载无关的:支持 protocol buffers、JSON、XML 和 Thrift。
- 流:Streaming API,一边传输,一边读取,不用等大文件传输完再读取。
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列。
- 元数据交换:类似http header,提升扩展性。常见的横切关注点,如认证或跟踪,依赖数据交换。还可以进行染色标记,构建多套环境。
- 标准化状态码:客户端通常以有限的方式响应 API 调用返回的错误。约束状态码名称空间,以使这些错误处理决策更加清晰。
gRPC VS Restful
- 相对于直接定义restful接口的优势:接口定义更加明确,请求体、响应体通过message定义出来,而直接定义restful接口,体现方式不统一,接口文档(维护性差)?第三方平台?服务端直接定义+swagger?都比较麻烦。
- restful采用http1.0,内部服务调用是很频繁的,开销较大。而gRPC基于http2.0,可以复用tcp连接。
-
json序列化没有pb性能好。
最近和其他团队联调一个新restful接口,发现接口里的字段类型和接口文档里定义的有差异(并不是没有更新接口文档,就是对方接口开发的有问题),导致浪费了彼此的时间。
也反映了一个问题,restful不是强约束,接口实现和文档定义可能存在差异。而gRPC就不会,接口通过pb定义好后,再根据pb自动生成客户端、服务端的代码,不会造成定义和实现不同的问题。
服务监控检查
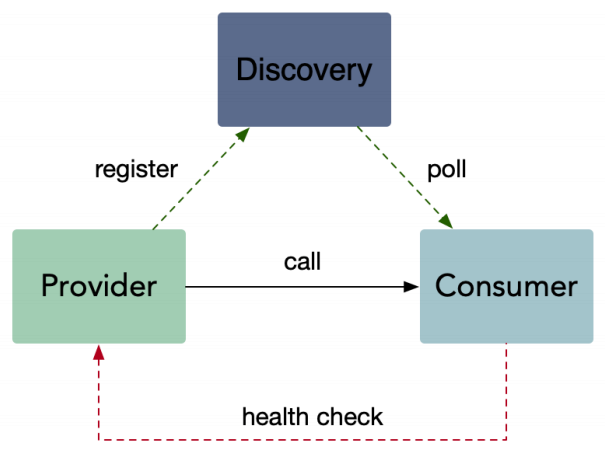
消费者可以直接感知提供者的状态,保障消费者和注册中心网络不稳定的情况下,也能及时将异常服务提供者从本地负载均衡池中移除。同理,提供者正常运行后,也能被消费者感知,重新加入负载均衡池。
gRPC - HealthCheck
gRPC 有一个标准的健康检查协议,默认提供用于设置运行状态的功能。
使用示例
client
echoClient := pb.NewEchoClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
r, err := c.UnaryEcho(ctx, &pb.EchoRequest{})
if err != nil {
fmt.Println("UnaryEcho: _, ", err)
} else {
fmt.Println("UnaryEcho: ", r.GetMessage())
}server
healthcheck.SetServingStatus(serverName, healthpb.HealthCheckResponse_SERVING)健康检查引发的问题
某些热点服务的依赖服务众多,依赖服务是多节点的,那么热点服务的每个节点需要对很多节点做健康检查。B站出现的情况是,仅健康检查就需要消耗30%CPU。
谷歌的子集算法
每个客服端只分配服务端集群中的子集,不用去使用全部服务端节点,这样健康检查也只对子集节点检查即可。
- 后端平均分给客户端。
- 客户端重启,保持重新均衡,同时对后端重启保持透明,连接的变动最小。
func Subset(backends []string, clientID, subsetSize int) []string {
subsetCount := len(backends) / subsetSize
// Group clients into rounds; each round uses the same shuffled list:
round := clientID / subsetCount
r := rand.New(rand.NewSource(int64(round)))
r.Shuffle(len(backends), func(i, j int) { backends[i], backends[j] = backends[j], backends[i] })
// The subset id corresponding to the current client:
subsetID := clientID % subsetCount
start := subsetID * subsetSize
return backends[start : start+subsetSize]
}- round相同时,r.Shuffle排序结果相同。
- clientID必须连续。
- 该算法是在直接划分后端节点
subsetID := clientID % subsetCount的基础上,增加了一步重排序round := clientID / subsetCount,r.Shuffle(),使其更加均衡。
为什么增加排序操作就能更均衡?
假如客户端有c1-c6,后端s1-s9。每个客户端连接3个后端。也就是c1(s1,s2,s3),c2(s4,s5,s6)...c4(s1,s2,s3)。如果c1和c4挂了,s1,s2,s3就没有客户端连接了,导致不均衡。但是重新排序后,两个客户端连接同样的后端子集概率更小,就会减少这种情况出现的几率。
应用平滑发布
优雅终止
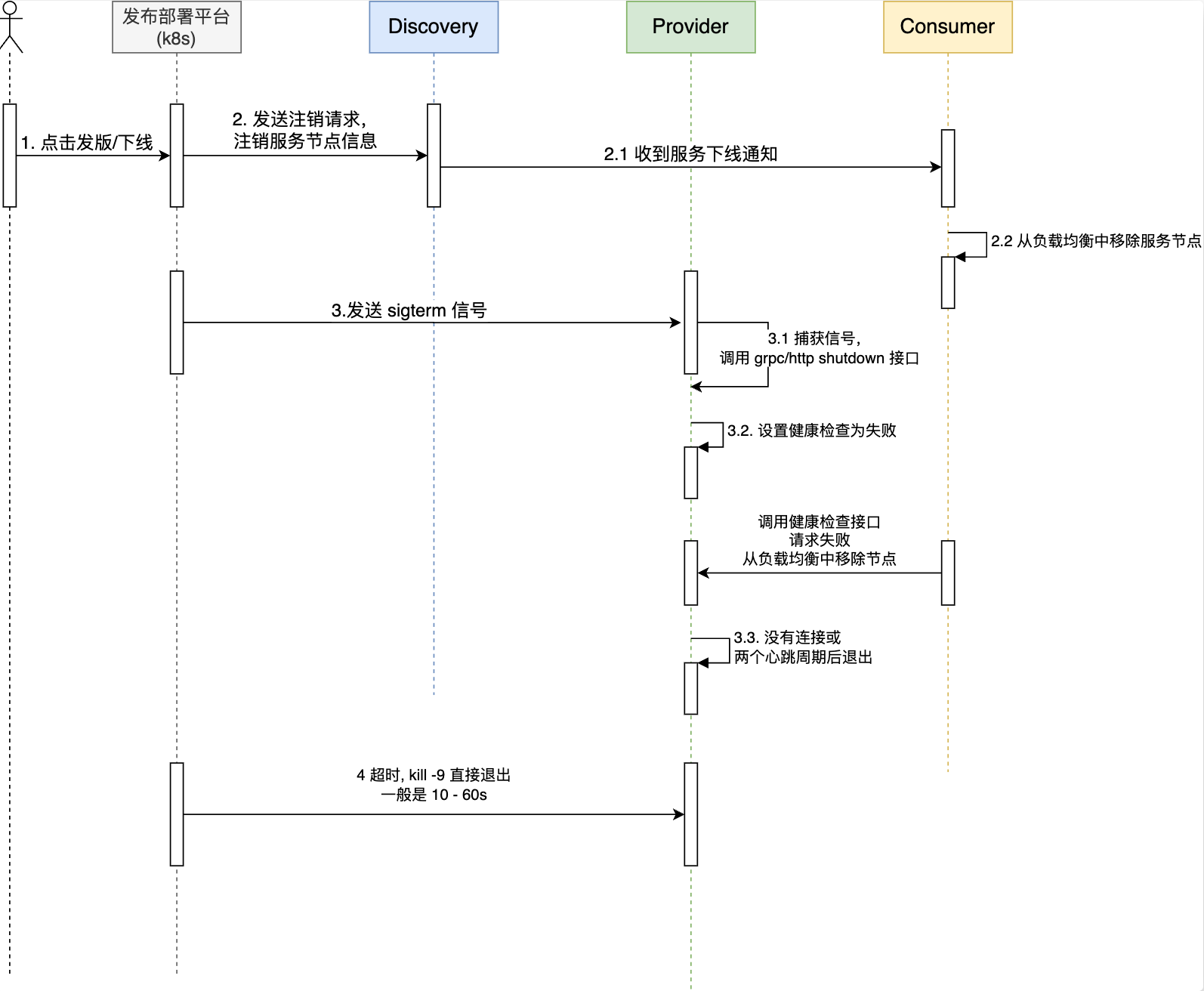
1.触发下线操作: 首先用户在发布平台点击发版/下线按钮
2.发布部署平台向注册中心发起服务注销请求,在注册中心下线服务的这个节点
- 这里在发布部署平台实现有个好处,不用每个应用都去实现一遍相同的逻辑
- 在应用受到退出信号之后由应用主动发起注销操作也是可以的
2.1注册中心下线应用之后,消费者会获取到服务注销的事件,然后将服务方的节点从本地负载均衡当中移除
注意这一步操作会有一段时间,下面的第四步并不是这一步结束了才开始
3.发布部署平台向应用发送 SIGTERM 信号,应用捕获到之后执行
- 将健康检查接口设置为不健康,返回错误
- 这个时候如果消费者还在调用应用程序,调用健康检查接口发现无法通过,也会将服务节点从本地负载均衡当中移除
- 调用 grpc/http 的 shutdown 接口,并且传递超时时间,等待连接全部关闭后退出
- 这个超时时间一般为 2 个心跳周期,保证没有被注册中心通知到的消费者感知到,避免流量进入。
4.发布部署平台如果发现应用程序长时间没有完成退出,发送 SIGKILL 强制退出应用
- 兜底
- 这个超时时间根据应用进行设置一般为 10 - 60s
优雅启动
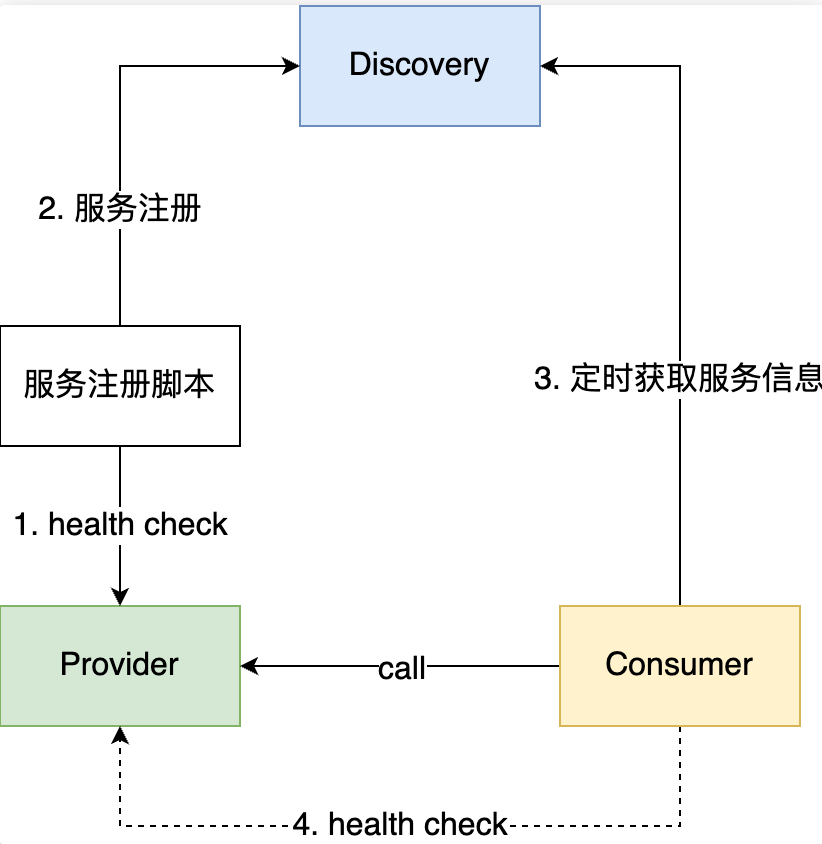
- 创建容器
- 通过外挂的方式,检查应用状态。
- 应用启动完毕后,设置gRPC服务状态设置为健康。
- 外挂的辅助脚本检测到应用健康,进行注册到注册中心。
- 消费者定时从服务注册中心获取服务方地址信息
- 获取成功后,会定时的向服务方发起健康检查,健康检查通过后才会向这个地址发起请求
- 在运行过程中如果健康检查出现问题,会从消费者本地的负载均衡中移除
为什么不是应用自己去注册?
剥离注册功能,下沉到辅助脚本里。避免所有应用(不同语言)都需要配置、提供注册功能。
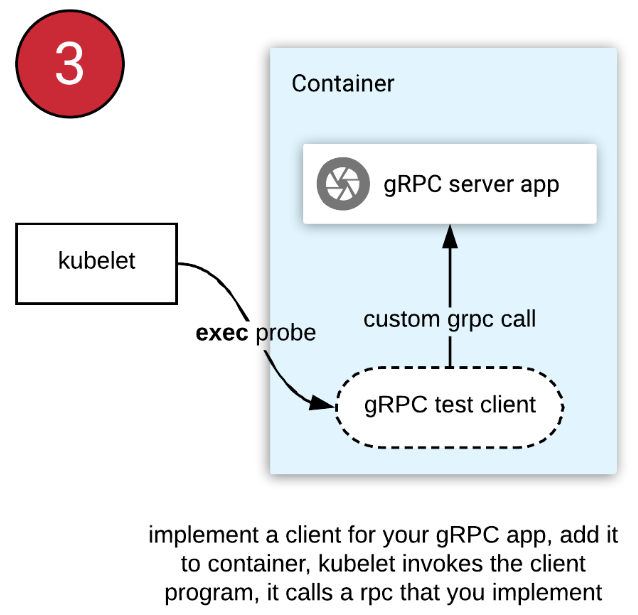
为什么不直接使用k8s的探针来检测应用健康?
因为k8s 1.23以前不支持检测gRPC服务,只能发送http请求,或者是检测TCP端口的连通性。
k8s 1.23 以前如何检测 gRPC 服务状态?
服务发现
客户端发现
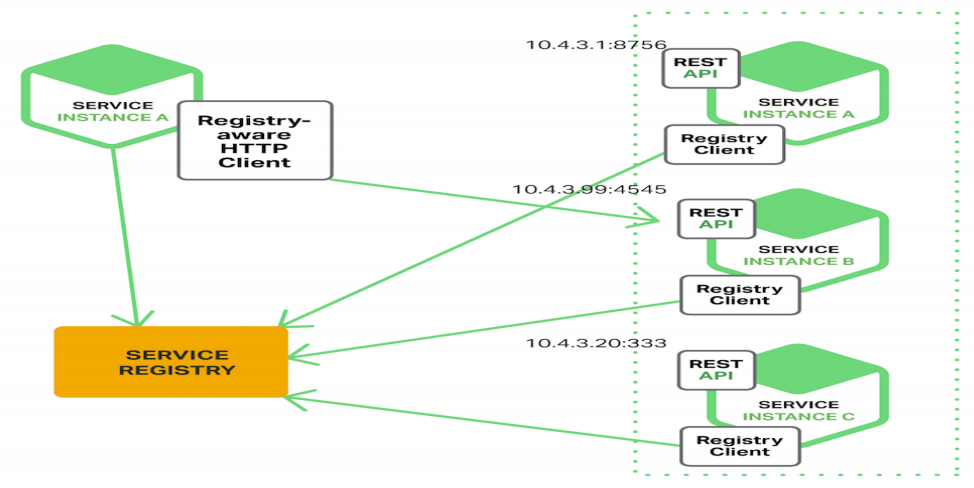
由注册中心做服务发现,并下发服务注册表到消费者,负载均衡在客户端完成。
- 去中心化——微服务核心理念
- 直连,性能更好
- 缺点:需要所有应用内置本地负载均衡组件,不同语言的应用,使用的负载均衡组件还不同。可使用service mesh优化,在k8s中使用sidecar来做负载均衡,从应用中独立出来,下沉为单独组件。
- ribbon就是这么干的,之前有写过博客:【SpringCloud】五、Ribbon
服务端发现
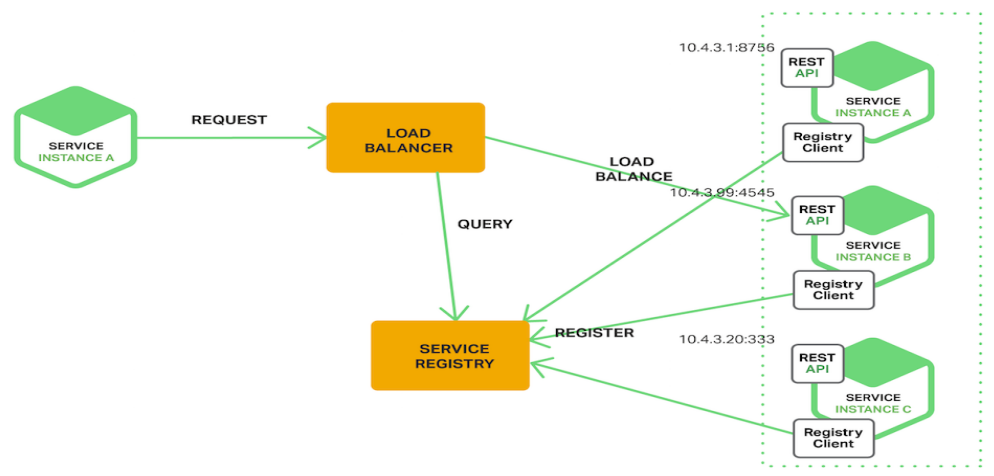
由注册中心做服务发现,并提供一个负载均衡器,从注册中心查询服务注册信息,客户端统一请求负载均衡器。
- 类似设计模式里的中介模式的概念。
- 应用无需关心负载均衡如何实现。
- 流量热点,如果使用nginx做负载均衡,单个nginx承受不住,还得使用
lvs+nginx集群,增加复杂度。 - 相关实现有:
Consul Template+Nginx,kubernetes+etcd
各注册中心对比
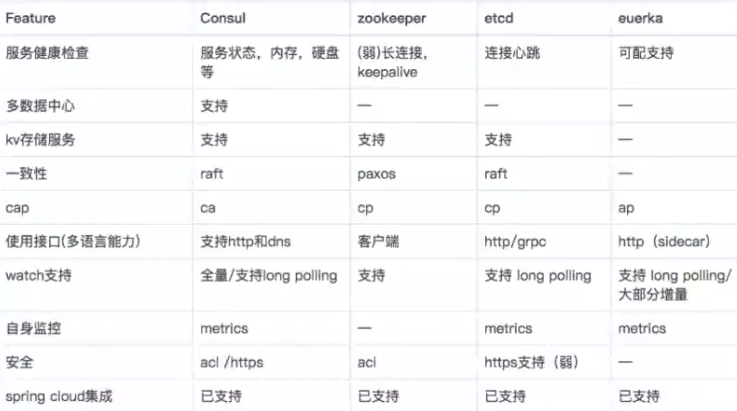
B站为什么从zookeeper切换到eureka?
zk保证了写操作一致性、分区容错。但leader节点挂掉后,会进行选举新的leader节点。期间整个zk是不能对外提供服务,大概会持续几十秒。从而失去可用性。并且大量服务长连接导致性能瓶颈。
而使用gRPC的服务发现这个场景下,一致性是可以弱一点的,带来的影响是:1、消费者没能拿到新注册的提供者地址,那就等一会呗。2、消费者拿到已注销的提供者地址,由于做了gRPC健康检查,并不会去调用该服务,会选择存活的服务。
而eureka就属于AP阵营,保证可用性,没有主节点,其他节点都挂掉,只剩一个节点也能对外提供服务。
eureka实现原理
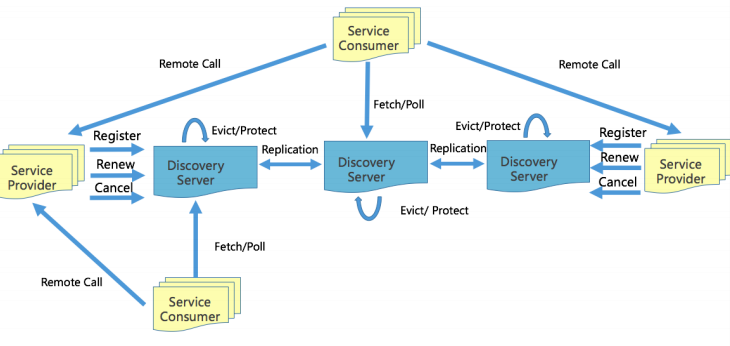
服务注册
- 服务方启动后向注册中心任意一个节点发送注册请求,然后这个节点会向其他节点进行广播同步。
- 通过 Family(appid) 和 Addr(IP:Port) 定位实例,除此之外还可以附加更多的元数据:权重、染色标签、集群等。
- appid: 使用三段式命名,business.service.xxx
- Provider 注册后定期(30s)心跳一次,注册,心跳,下线都需要进行同步,注册和下线需要进行长轮询推送。
- 新启动节点,需要 load cache,JVM 预热。
服务发现
- Consumer 启动时拉取实例,发起30s长轮询。故障时,需要 client 侧 cache 节点信息。
- 长轮询:客户端发送请求拉取数据,如果此时服务端没有产生的数据,就不暂时不响应,等有数据或者达到超时时间(例如30秒),再响应。也就是这个请求会挂起。有效减少轮询场景下的请求数量。
网络故障
服务方与注册中心
- 注册中心会定期(60s)检测已失效(90s 未更新)的实例,失效之后就会移除,但是如果短时间内丢失大量心跳连接,(15min 内心跳低于期望值的 85%)就会开启自我保护模式,保留过期的服务不会进行删除
注册中心与消费者
- 消费者本地有缓存,问题不大
服务方与消费者
- 有健康检查,健康检查不通过时,会从消费者本地负载均衡中移除
注册中心故障
- 不建议这个时候服务进行重启或者是发版,因为这个时候注册不上,会导致服务不可用,不发版短时间没有影响。
- 某个eurak挂了,不要马上主动重启,因为新启动的enuraka里没有任何服务注册信息,这时候有服务来拉取服务注册信息,就会导致该服务无法访问其他服务。如果立即重启,需要做控制,例如启动后等待数据同步完毕才对外提供服务。
- 全部eureka节点都挂了,全部重启后,需要等待2、3个心跳周期,等服务都注册好后,在对外提供查询服务。
- 数据同步时会对比时间戳,会保证当前节点的数据是最新的
B站用Go重写了eureka,做了些改进,上诉部分内容可能是B站改进后的。
其他
多个微服务共享db
微服务中大部分是独占db,也有sharedatabase的情况,例如:具有高级权限的admin服务和面向用户的服务共享db
网关层如何收敛客户端多版本?
可通过请求的header进行路由
微服务之间的服务调用理论上是有向无环图(DAG, Directed Acyclic Graph),如何避免闭环调用?
通过链路追踪得到服务调用关系图,并在服务调用申请权限时进行阻止。
简单接口也要在BFF层定义吗?
BFF支持直接透传,例如一些简单的接口,不需要在BFF做什么,只需调用业务中台的服务就行。但流量还是不能直接从网关层到业务中台,需要在BFF配置路由,让流量经过BFF再到业务中台。