存储设计

comment_subject
抽象的主题表,把评论的主体抽象出来,包含专有属性,例如state。
-
id:mysql必须有主键,不建立主键mysql也会提供一个rowId- 使用自增,为了顺序存储,提高读写性能。
- 索引搜索快还是主键搜索快?
- 索引搜索是根据索引字段找到主键,再通过主键去找到记录,也就是二级索引。
- 用递增int不会带来安全性问题吗?
- 会的,可通过API加密解决
- InnoDB默认是行级别的锁,当有明确指定的主键时候,是行级锁。否则是表级别。
-
obj_type:冗余了对象类型字段,这个字段不会改变,可减少连表查询,空间换时间的思想。 -
member_id:也是冗余字段 -
count:这个字段很常用,前端用于分页查询或展示用,可避免使用count(*)。- 哪些情况下,适合额外记录这个count?
-
state:使用int8,节约存储空间- 但是pb只支持int32、int64,如果数据库使用int8,会导致项目里很多地方需要做类型转换。
-
attr:这个字段有点巧妙,利用32bit的int32,表示32个非0即1的属性。- 这样做解析、使用时会不会不好做?例如要取某个属性,需要做一个位运算,感觉也还好。
- 也不一定是非0即1,可以多占几位
- 优点
- 节约空间
- 扩展性强
- 加字段有哪些坏处?
- 什么情况下适用呢?
-
0-49
- sharding:分片、分表,数据量大的情况下使用。
- 根据
obj_id、obj_type进行分表,保证一个评论对象的所有评论都在一张表,并且能快速定位到。良好的分表不会存在join子表的操作。 - 拆完表后,使用mysql的自增id会重复,可使用另外的唯一、顺序自增的id生成器。
-
create_time:每张表都有创建更新时间
comment_index
评论索引表,和包含大字段的评论内容表拆开
-
不过这两张表的使用场景,应该是同时需要的,那还有必要拆开吗?有必要的
- mysql io以页为单位,一页16k,把大字段拆开后,索引表读取性能高很多
- 索引表会涉及排序操作
- 大字段表后期太大了后,可以放到KV数据库里
- 这种套路以前和阿里大佬交流时也提到过。
- 这里不仅是大小分离,还有动静分离。不怎么变更的数据放一张表,经常变更的数据放一张表,方便 mysql datapage 缓存更多的 row。
-
obj_id:对象id- 为什么没有通过
comment_subject的id进行关联?依旧使用的是obj_id
- 为什么没有通过
-
obj_type:冗余字段 -
state:达到逻辑删除的目的,也可以使用gorm的逻辑删除特性。- 这里理念有些不同,毛老师建议线上数据不用物理删除,而我上家公司的开发规范要求不要使用逻辑删除。做删除功能的时候多考虑下业务吧!
comment_content
评论内容表
comment_id:直接用的索引表的id,而没有重新建立一个主键,避免上诉的二级索引问题。
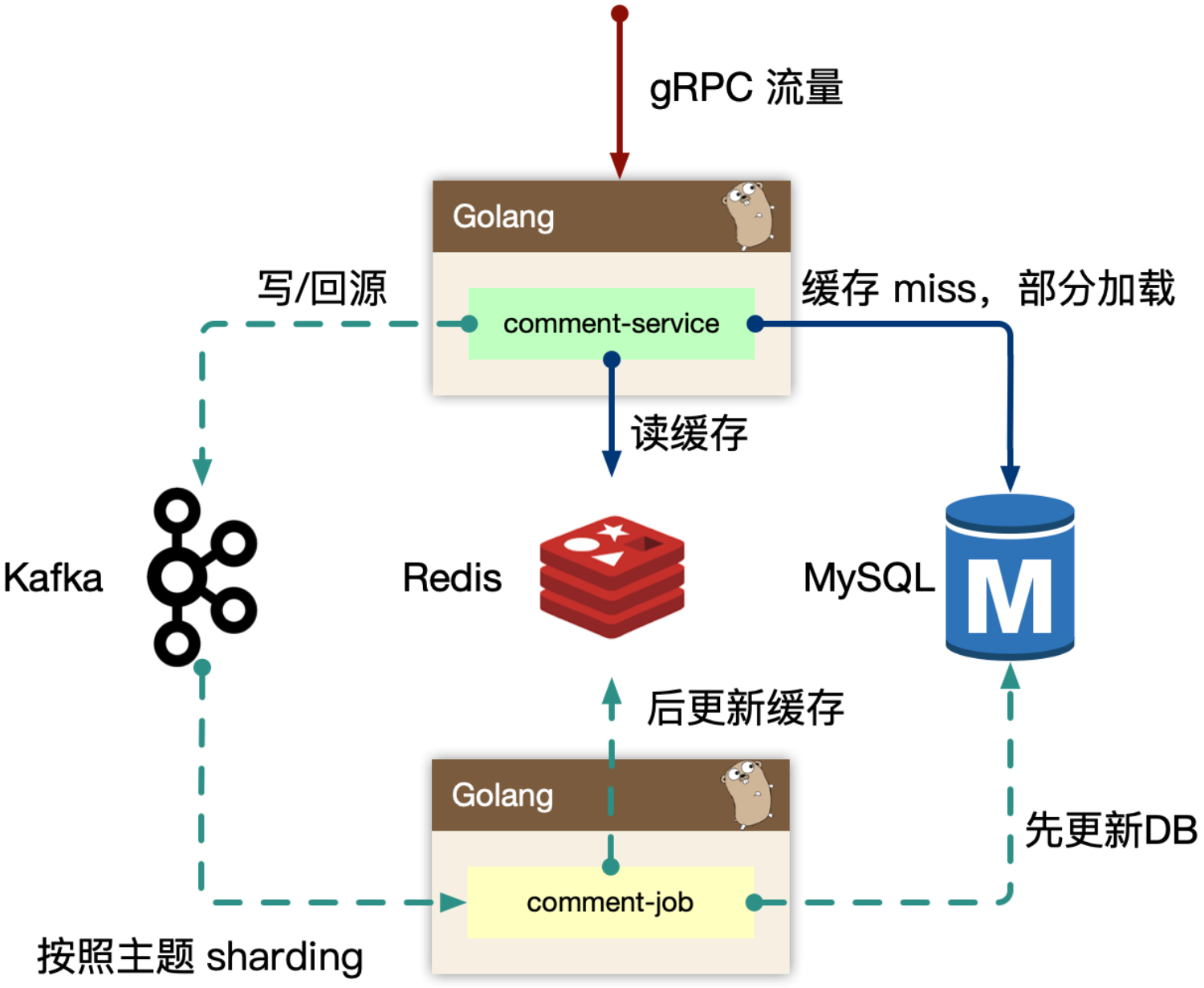
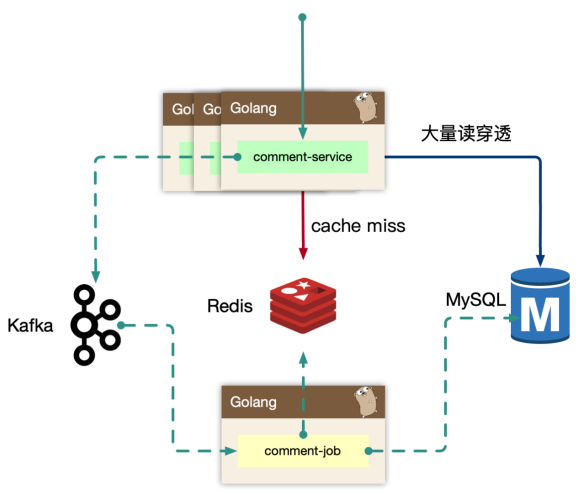
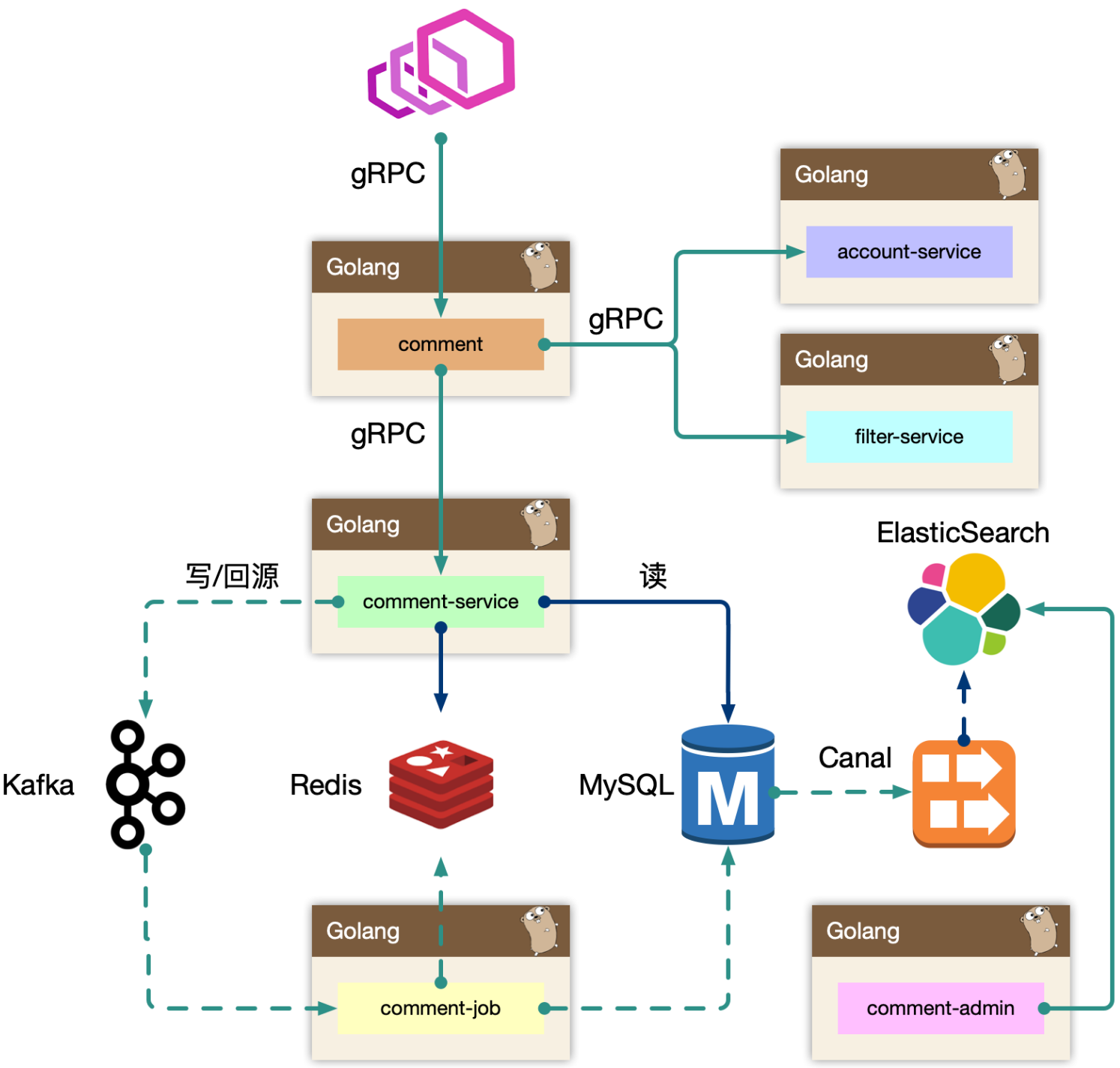
数据写入
事务更新 comment_subject,comment_index,comment_content 三张表,其中 content 属于非强制需要一致性考虑的。可以先写入 content,之后事务更新其他表。即便 content 先成功,后续失败仅仅存在一条 ghost 数据。这样做虽然性能没有提升多少,但是content表是有可能替代为KV数据库的。
数据读取
新增评论时,通过事务,对subject表和index表的count进行+1,需要先读取,再更新,i++问题。此时会有并发问题,导致count不对。可通过for update读取,会触发行级锁,和更新操作在一个事务里,只有等事务结束后,其他事务才能读取这行记录。
基于 obj_id + obj_type 在 comment_index 表找到评论列表,WHERE root = 0 ORDER BY floor(where order字段要加索引,order不加索引会导致查询结果需要在内存排序,如果排序缓存太小,还会在磁盘里排序,性能很差,一般要避免)。之后根据 comment_index 的 id 字段捞出 comment_content 的评论内容。对于二级的子楼层,WHERE parent/root IN (id...),这里一级评论的id不会太多,前面查一级评论并不是全查,只查几页(预读)。
因为产品形态上只存在二级列表,因此只需要迭代查询两次即可。对于嵌套层次多的,产品上,可以通过二次点击支持。
针对评论系统,不用做跨页读取。不管是PC还是移动端,都是用瀑布流,懒加载,游标分页的方式来做。数据量很大的情况,对性能有很大帮助。k8s的API,例如ListEvent,也不支持指定页码,只能获取next页。而且谷歌api设计指南里针对分页接口,也只做了这种游标分页。
缓存设计
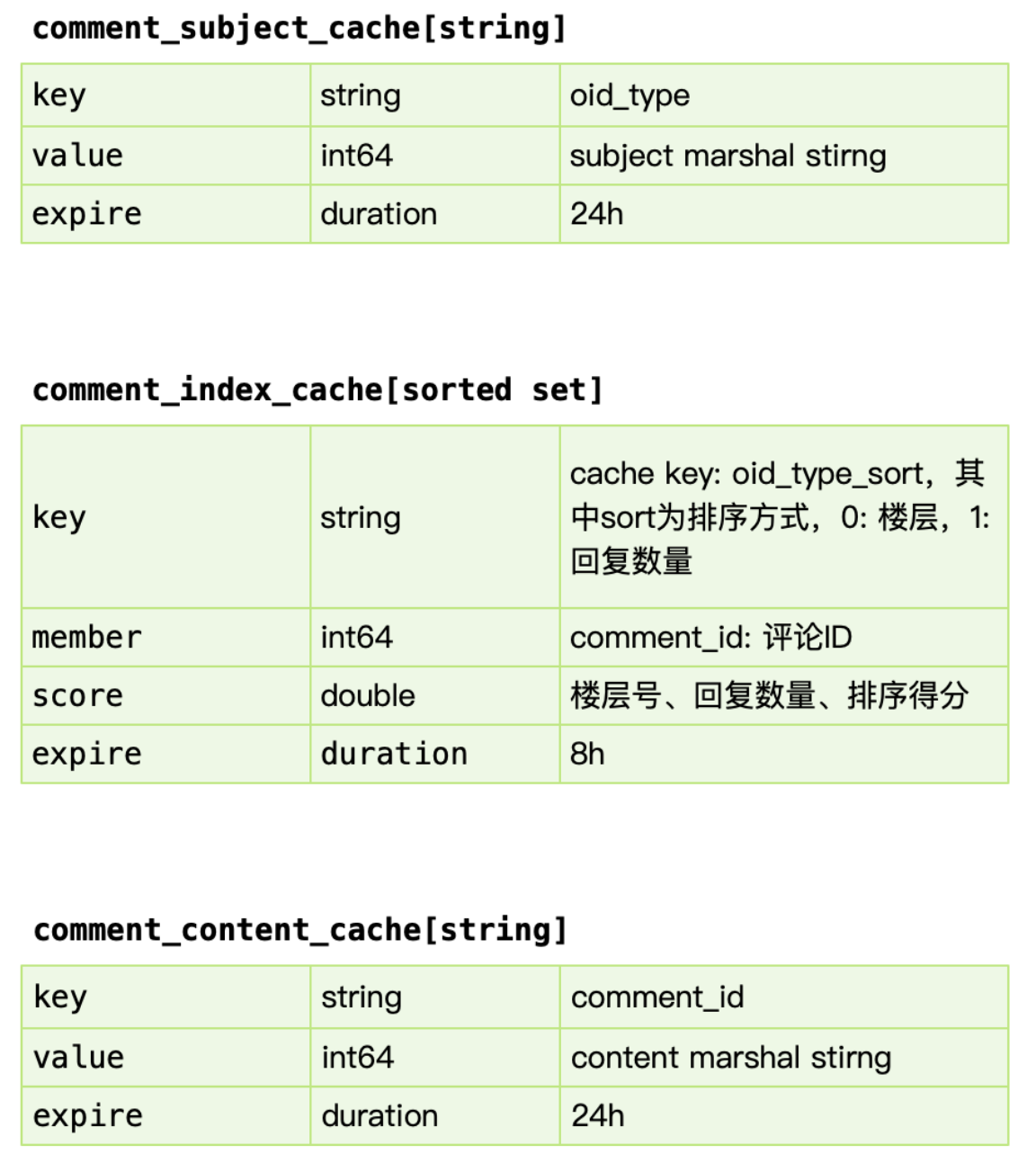
comment_subject_cache:
- 对应主题的缓存,value 使用 protobuf 序列化的方式存入,比json体积小,效率高。
comment_index_cache
-
使用 redis sorted set 进行索引的缓存,索引即数据的组织顺序,而非数据内容。参考过百度的贴吧,他们使用自己研发的拉链存储来组织索引,我认为 mysql 作为主力存储,利用 redis 来做加速完全足够,因为 cache miss 的构建,我们前面讲过使用 kafka 的消费者中处理,预加载少量数据,通过增量加载的方式逐渐预热填充缓存,而 redis sortedset skiplist 的实现,可以做到 O(logN) + O(M) 的时间复杂度,效率很高。
-
sorted set 是要增量追加的,因此必须判定 key 存在,才能 zdd。如果先判断exist后,再zdd追加到Redis sorted set里,两个步骤之间可能key过期了。解决方案:不去判断,直接先续期。
-
索引表缓存,增量加载+lazy加载,缓存miss时,进行查库,预读(通过评论对象表得知是否还有数据),增量缓存。
-
key:oid_type_sort,sort为排序方式,0:楼层,1:回复数量。冗余设计,空间换时间。
-
redis sorted set 支持 range 读取,对分页查询友好。但不能一次读取太多数据,redis 读写是单线程。
-
range读取索引缓存后,再pipline批量获取内容缓存,减少IO。
- redis pipline命令:客户端将多个命令打包一次性发送给服务器,全部执行完毕后再一起返回到客户端,减少网络IO。
comment_content_cache
- 对应评论内容数据,使用 protobuf 序列化的方式存入。