Singleflight
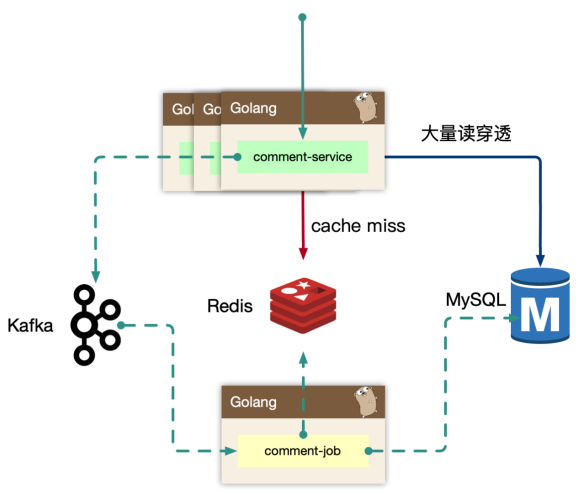
对于热门的主题,如果存在缓存穿透的情况,会导致大量的同进程、跨进程的数据回源到存储层,可能会引起存储过载的情况,如何只交给同进程内,一个人去做加载存储?
使用归并回源的思路:https://pkg.go.dev/golang.org/x/sync/singleflight,同一时间只有一个协程去拿数据,拿到数据前,相同任务目标的其他协程都阻塞,拿到数据后,所有协程一起返回。
同进程只交给一个人去获取 mysql 数据,然后批量返回。同时这个 lease owner 投递一个 kafka 消息,做 index cache 的 recovery 操作。这样可以大大减少 mysql 的压力,以及大量透穿导致的密集写 kafka 的问题。这是单个进程内的Singleflight,多节点下也会出现重复构建缓存的情况。可通过kafaka根据objId和objType进行分发消息,保证同一个缓存构建任务都分发到同一个job进程,同时这是串行执行,每次执行前先判断下缓存内是否有miss的key,有的话就drop当前任务。
这种套路很常见,例如CDN避免大量请求到源站,可能会使用多级单飞节点。
为什么不用分布式锁之类的思路?
太复杂,一般锁的key很快就过期了,不好调试。
极端情况下如何保证高可用
- redis集群
- 对mysql的操作做熔断
热点
读热点
流量热点是因为突然热门的主题,被高频次的访问,因为底层的 cache 设计,一般是按照主题 key 进行一致性 hash 来进行分片,但是热点 key 一定命中某一个节点,这时候 remote cache 可能会变为瓶颈,因此做 cache 的升级 local cache 是有必要的,我们一般使用单进程自适应发现热点的思路,附加一个短时的 ttl local cache,可以在进程内吞掉大量的读请求。牺牲短时间的一致性,例如1秒,用户不容易感知。
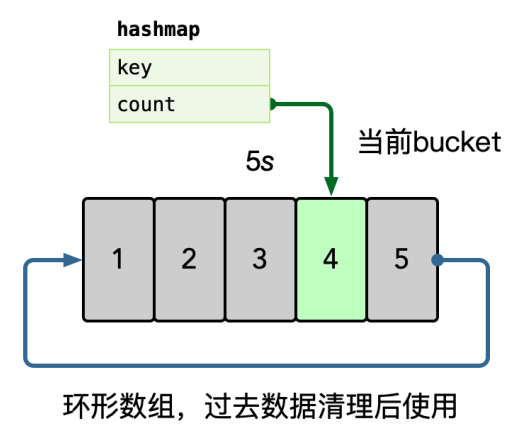
在内存中使用 hashmap 统计每个 key 的访问频次,这里可以使用滑动窗口统计,即每个窗口中,维护一个 hashmap,之后统计所有未过去的 bucket,汇总所有 key 的数据。之后使用小堆计算 TopK 的数据,自动进行热点识别。
一个统计周期拆分成多个窗口的原因是用平均值削平毛刺qps(在某个点突发的qps)对整体的影响。
写热点
- job里有推送消息到某个用户的操作,对某个用户的评论进行大量评论时,这个推送操作下游服务处理太慢,从而影响job服务对kafaka的消费能力下降,最终导致这个kafaka partion的任务都受影响。解决方案:
- 抽取推送操作为单独服务,通过读取写评论后的mysql binlog,进行异步操作。
- 优化分发partion,虚拟出更多的partion。


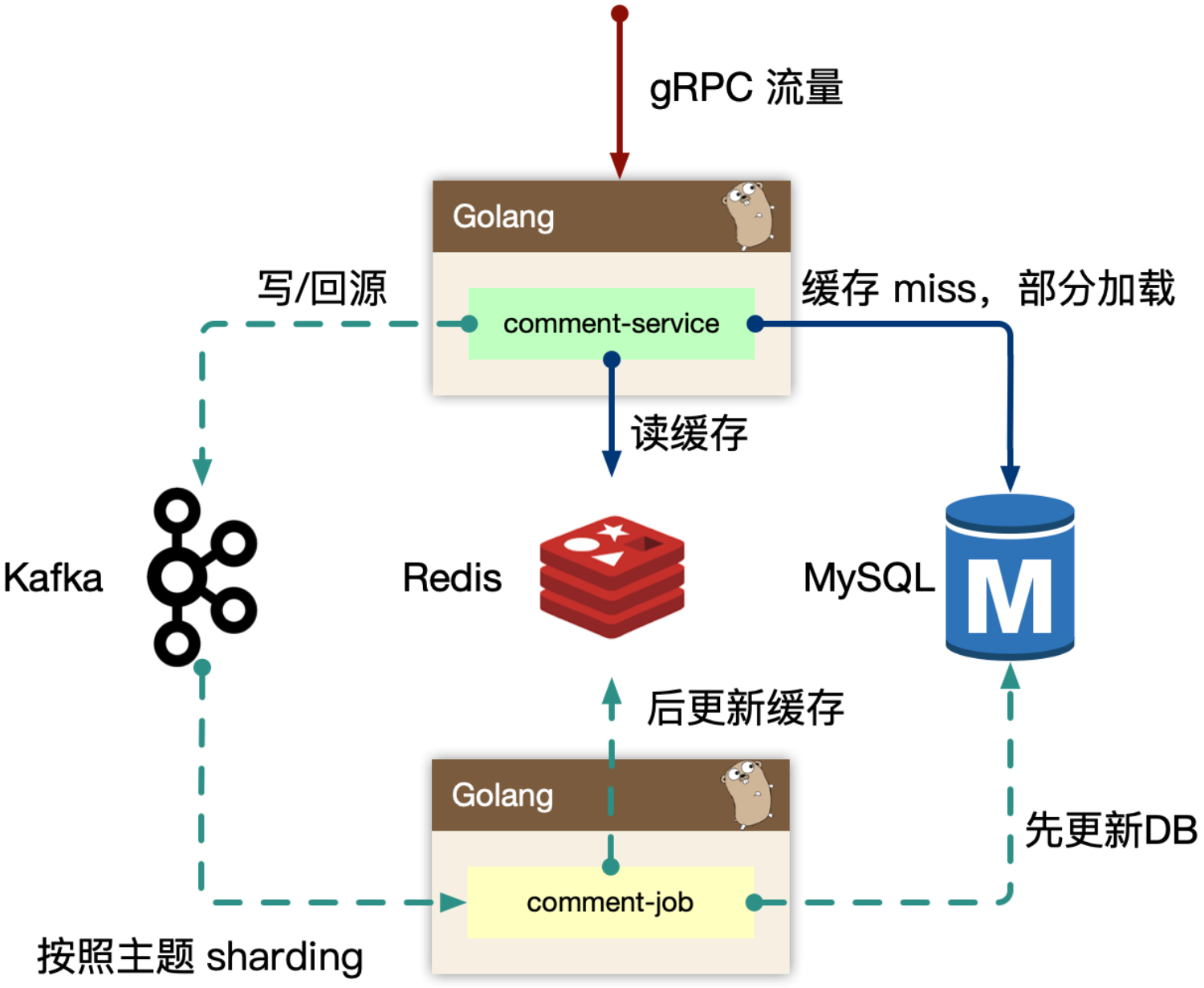
请问有具体的实现吗?
没有哈,主要是理论知识
你好,我想请问一下,你知道毛剑老师用的那个画图工具是什么吗?我记得他说过,但是忘了在那个地方说的了,找不到了
好像是这个:https://www.omnigroup.com/omnigraffle/
另外推荐你个:draw.io
好的 感谢啊