API 定义文件放在哪?
放在当前项目
使用时,需要import此项目,造成API和源码绑定,不好单独管理权限。
放在当前项目,并通过CI自动同步到API大仓——B站的方案
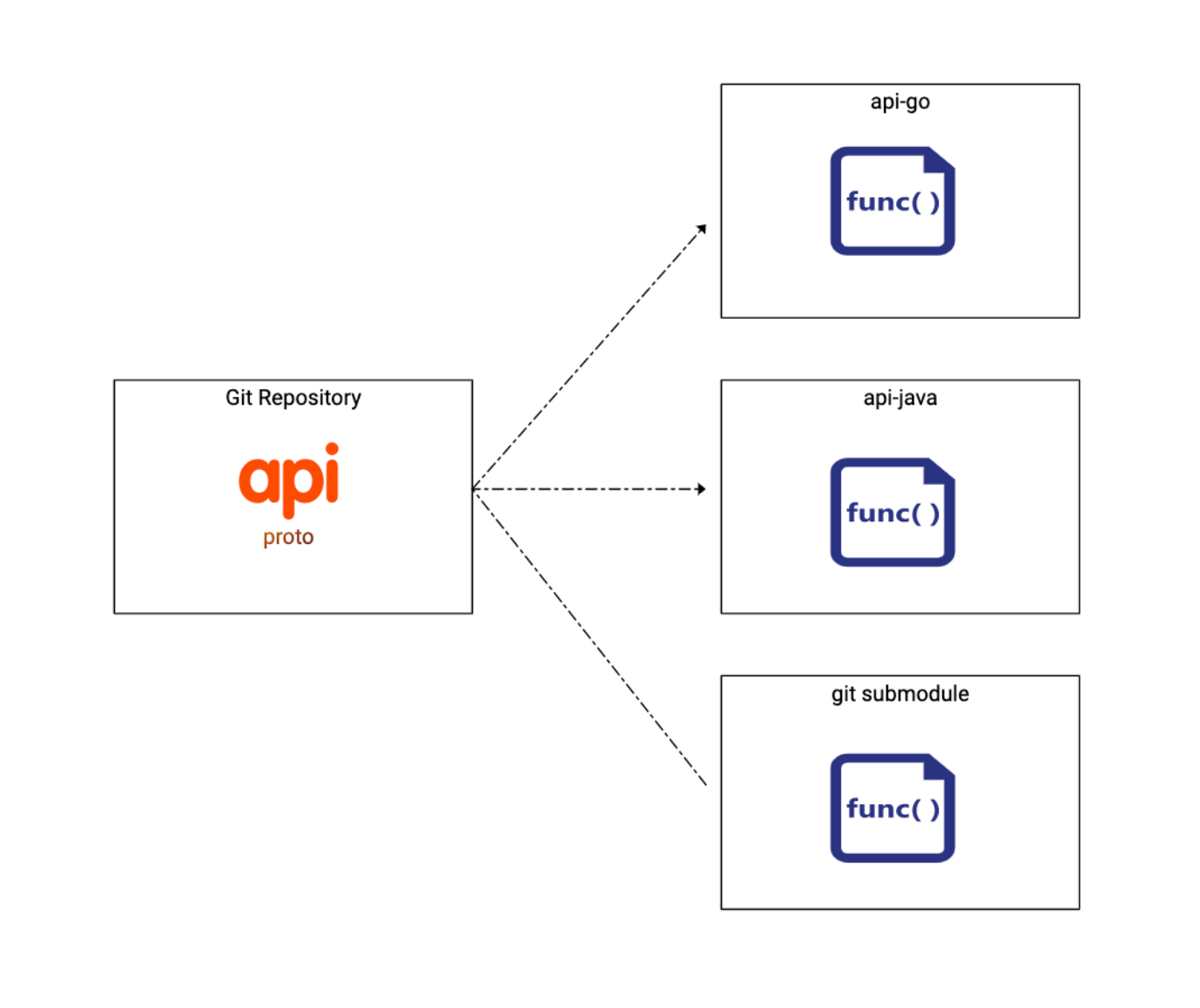
为了统一检索和规范 API,B站内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。
参考
优点
- 所有 API 定义放到同一个地方,方便跨部门协作。
- 版本管理,基于 git 控制。
- 规范化检查,API lint。
- API design review,变更 diff。
- 目录里存放 OWNERS 文件,结合Gitlab CI,达到权限管理的目的。
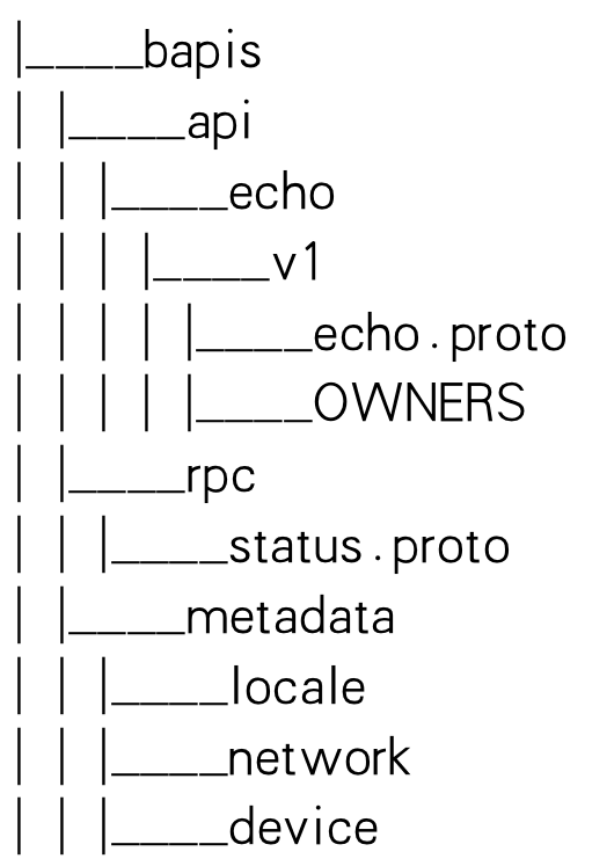
目录结构
-
项目中定义 proto,以 api 为包名根目录

-
在统一仓库中管理 proto ,以仓库为包名根目录:
-
整个API大仓的目录结构
- rpc:内部状态码
- metadata:框架元信息
- service:业务服务接口
- owners:权限拥有者


落地实践
这里的 API 大仓方案在我司进行了落地实践:Gitlab CI/CD 实践六:统一管理 protocol buffer,API 大仓设计与实现
API 兼容性
在存在移动端的情况下,或者是对外提供的 API,兼容性很重要的一点,毕竟客户端升级不可控。但如果是内部服务,升级可控的情况下,就可以放心重构、修改。
向后兼容(非破坏性)的修改
-
新增 API 接口
-
新增请求字段
-
新增响应字段
在不改变其他响应字段的行为的前提下,非资源(例如,ListBooksResponse)的响应消息可以扩展而不必破坏客户端的兼容性。即使会引入冗余,先前在响应中填充的任何字段应继续使用相同的语义填充。如果是资源对象,就要注意是否被其他地方引用。
-
请求、响应消息定义专属message,不要使用Google的empty message
- 原本是向后兼容的修改也会导致不兼容。例如添加一个字段,就需要创建新的message,从而影响兼容性。
向后不兼容(破坏性)的修改
-
删除或重命名服务,字段,方法或枚举值
从根本上说,如果客户端代码可以引用某些东西,那么删除或重命名它都是不兼容的变化,这时必须修改 major 版本号。
-
修改字段的类型
即使新类型是传输格式兼容的,这也可能会导致客户端库生成的代码发生变化,因此必须增加 major 版本号。 对于编译型静态语言来说,会容易引入编译错误。
-
修改现有请求的可见行为
客户端通常依赖于 API 行为和语义,即使这样的行为没有被明确支持或记录。 因此,在大多数情况下,修改 API 数据的行为或语义将被消费者视为是破坏性的。如果行为没有加密隐藏,您应该假设用户已经发现它,并将依赖于它。
-
给资源消息添加 读取/写入 字段
- 例如put方法里的参数增加字段,可能会导致库里该字段被零值覆盖。
不理解 读取 字段为什么影响兼容性
-
单个接口发生向后不兼容的修改时,可将改接口函数改为xxxV2。如果很多接口都发生破坏性修改,可直接建立V2目录。
API 名名规范
命名规则:方法 + 资源,主要是参照Google的 API 设计指南

| 标准方法 | HTTP 映射 |
|---|---|
| List | GET |
| Get | GET |
| Update | PUT 或者 PATCH |
| Create | POST |
| Delete | DELETE |
包名:company.app_id.version
-
APP_ID:为应用的标识,B站采用的是
business.service.xxx,例如account.service.vip。我们团队采用的是gitlab组.项目名.微服务类型。 -
和所在目录对应,buf的lint检查会检查这个。
http2.0 RequestURL
/<package_name>.<version>.<service_name>/{method}
一个实现绑定多个接口
service BlogService {
rpc ListArticles(ListArticlesReq) returns (ListArticlesResp) {
option (google.api.http) = {
get: "/v1/articles"
additional_bindings {
get: "/v1/author/{author_id}/articles"
}
};
}
}additional_bindings:更新时可同时绑定put和patch。- 这里的列表查询,即支持查询全部,也支持查询某个父级领域下的全部。
- 开放查询全部接口时,需要考虑该表的数据量。
API 基础类型字段
基础类型字段指int32、string等非指针字段,由于某些语音特性,导致无法区分零值和默认值。例如Java里的基础类型都有对应的包装类,但Go里没有。
gRPC 默认使用 Protobuf v3 格式,去除了 required 和 optional 关键字,默认全部都是 optional 字段。在V2中,如果是optional修饰的字段,可通过pb生成的hasXXX()函数判断是否传了这个字段。
解决方案
Google提供了在pb里的包装类实现:https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/wrappers.proto,例如double类型:
message DoubleValue{
double value = 1;
}在使用时就可以通过==nil判断是否为默认值。实际使用过程中很难用,需要对每个字段进行if != nil 判断。更好的做法是使用fieldMask,具体请看:todo。
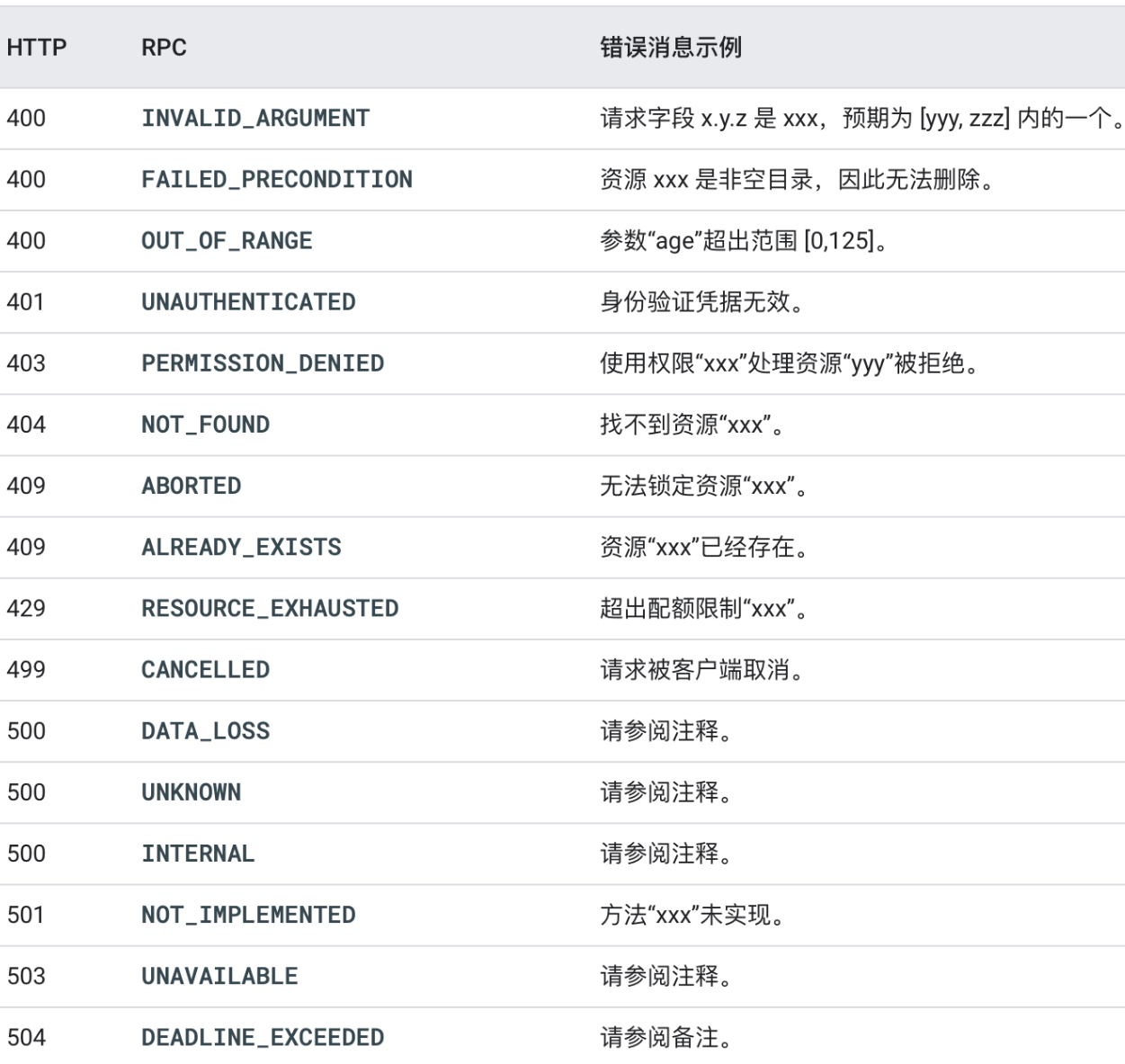
API 错误处理
使用 Http 状态码来描述错误。
-
状态码有利于监控,如果都是响应200,再通过body里的内容判断是否出错,监控系统就很难采集。
-
前端可通过状态码,结合try catch,很方便的处理异常。
-
http状态码毕竟有限,可结合接口层面定义的业务错误码枚举值使用。
message Status { // 错误码,跟 grpc-status 一致,并且在HTTP中可映射成 http-status int32 code = 1; // 错误原因,定义为业务判定错误码 string reason = 2; // 错误信息,为用户可读的信息,可作为用户提示内容 string message = 3; // 错误详细信息,可以附加自定义的信息列表 repeated google.protobuf.Any details = 4; }
使用一小组标准错误配合大量资源
http状态码或者gRPC错误码(这两个可以进行转化)
例如,服务器没有定义不同类型的“找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息(/google/rpc/error_details)。
除非业务需要(例如客户端需要判断是否为联系人找不到,还是其他资源找不到),才在接口层面定义具体某个资源找不到的错误。
错误传播
不应该将上游错误透传给下游,造成无法定位错误,或者影响当前服务和下游服务之间的错误处理逻辑。应翻译为当前服务的内部错误再进行传递。
全局错误码
全局错误码指在公司内部达成规约,1xxxx是某个服务的错误码范围,2xxxx是另一个服务的错误码范围,并将具体错误公示。达到透传错误时,能定位错误的效果。这是松散、易被破坏契约的。
这里是讲的API错误处理的指导思想,实际落地,可看Kratos错误处理实践:todo
更新接口问题
某些场景下,只需要更新个别字段,如果每个情况都写一个接口,工作量很大。只用一个接口统一更新,就得区分零值和默认值。
解决方案
通过传递fieldmask字段,来标识需要更新的字段,具体请看fieldmask实践:todo


求资源